SQL — что это, и какие плюсы использования этого языка?

SQL является инструментом, предназначенным для организации, управления, выборки и обработки информации, содержащейся в базе данных. Изначально в IBM этому языку было дано имя Structured English Query Language, сокращенно SEQUEL. Однако в тот момент владельцем торговой марки SEQUEL была компания Hawker Siddeley Aircraft Company из Великобритании, так что название языка было сокращено до SQL (Structured Query Language, язык структурированных запросов), а слово English было удалено из названия (для соответствия названия аббревиатуре). В настоящее время аббревиатура SQL читается либо как «сиквел», либо как «эс-кю-эль», причем корректны оба произношения, хотя предпочтительно второе. Как следует из названия, SQL является языком программирования, который применяется для организации взаимодействия пользователя с базой данных. На самом деле SQL работает только с базами данных определенного типа, называемыми реляционными базами данных, которые представляют собой основной способ организации данных в широком диапазоне приложений.
На рис. 1. показана схема работы SQL. Согласно этой схеме, в вычислительной системе имеется база данных, в которой хранится важная информация. Если вычислительная система относится к сфере бизнеса, то в базе данных могут содержаться сведения о материальных ценностях, выпускаемой продукции, объемах продаж и зарплате. В базе данных на персональном компьютере может находиться информация о выписанных чеках, телефонах и адресах или информация, извлеченная из более крупной вычислительной системы. Компьютерная программа, которая управляет базой данных, называется системой управления базой данных, или СУБД.
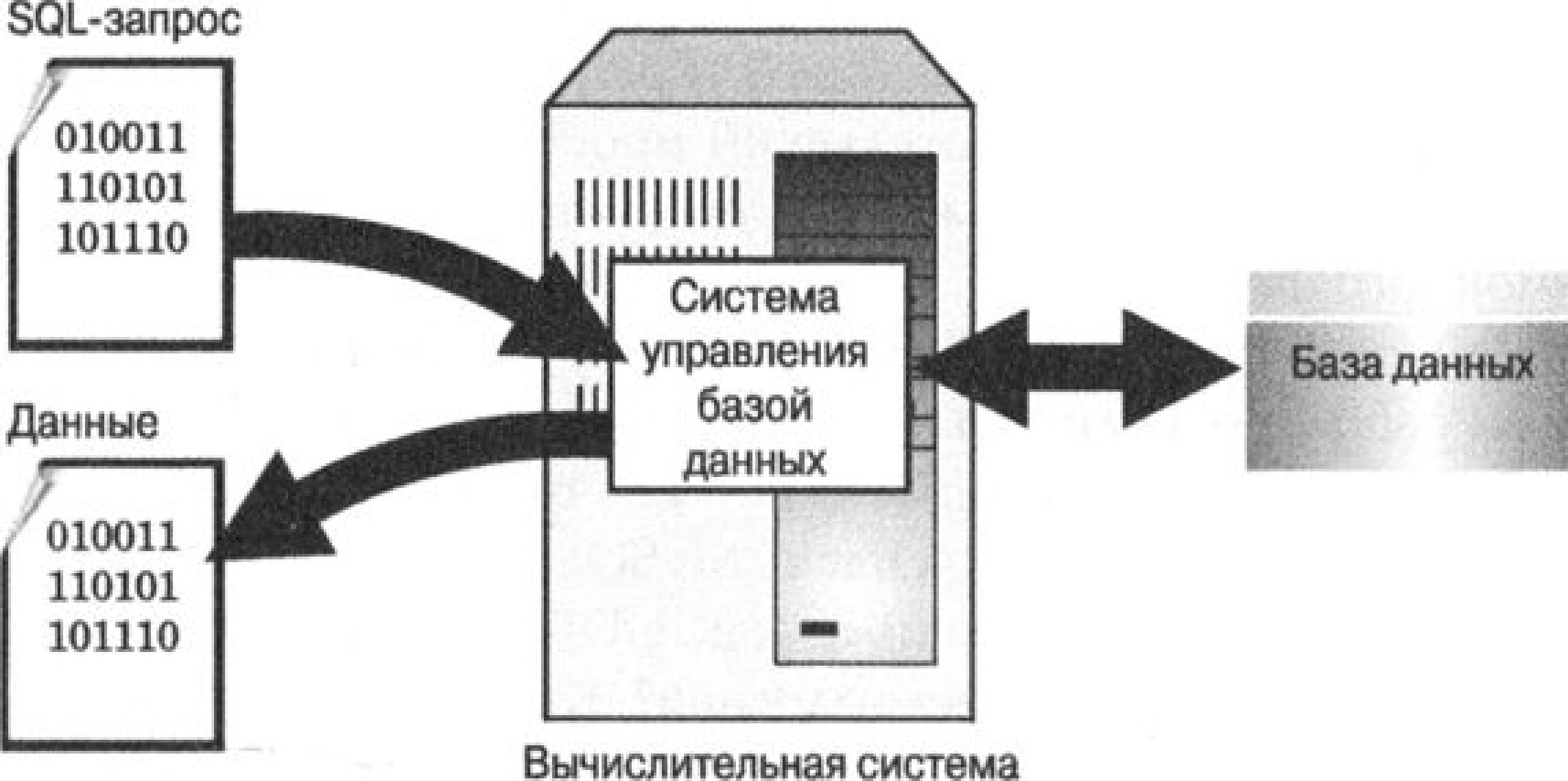
Рис. 1. Применение SQL для обращения к базе данных
Для того чтобы получить информацию из базы данных, вы запрашиваете ее у СУБД с помощью SQL. СУБД обрабатывает запрос, находит требуемые данные и возвращает их вам. Процесс запроса данных у базы данных и получения результата называется запросом к базе данных (вот почему в названии языка имеется слово «запрос» — язык структурированных запросов).
Однако это название не совсем соответствует действительности. Во-первых, сегодня SQL представляет собой нечто большее, чем просто инструмент создания запросов, хотя именно для этого он и был первоначально разработан. Несмотря на то что выборка данных по-прежнему остается одной из наиболее важных функций SQL, сейчас этот язык используется для реализации всех функциональных возможностей, которые СУБД предоставляет пользователю.
- Определение данных. SQL позволяет пользователю определить структуру и организацию хранимых данных и взаимоотношения между элементами сохраненных данных.
- Выборка данных. SQL дает пользователю или приложению возможность извлекать из базы содержащиеся в ней данные и пользоваться ими.
- Обработка данных. SQL позволяет пользователю или приложению изменять базу данных, т.е. добавлять в нее новые данные, а также удалять или обновлять уже имеющиеся в ней данные.
- Управление доступом. С помощью SQL можно ограничить возможности пользователя по выборке, добавлению и изменению данных и защитить их от несанкционированного доступа.
- Совместное использование данных. SQL применяется для координации совместного использования данных пользователями, работающими одновременно, с тем чтобы изменения, вносимые одним пользователем, не приводили к непреднамеренному уничтожению изменений, вносимых примерно в го же время иным пользователем.
- Целостность данных. SQL позволяет обеспечить целостность базы данных, защищая ее от разрушения из-за несогласованных изменений или отказа системы.
Таким образом, SQL является достаточно мощным языком для управления СУБД и взаимодействия с ней.
Во-вторых, SQL — это не полноценный компьютерный язык типа COBOL, С, C++ или Java. SQL является подъязыком баз данных, в который входит около сорока инструкций, предназначенных для решения задач управления базами данных. Эти инструкции SQL могут быть встроены в другой язык, такой как COBOL или С, и расширяют его, давая возможность получать доступ к базам данных. Кроме того, из такого языка, как С, C++ или Java, инструкции SQL можно посылать СУБД в явном виде, используя интерфейс на уровне вызовов функций (call-level interface) или отправляя сообщения по вычислительной сети.
SQL отличается от других языков программирования, поскольку он описывает, что пользователь хочет от компьютера, а не как компьютер должен это сделать. (Говоря технически, SQL является декларативным, или описательным, а не процедурным языком.) В SQL нет инструкции IF для проверки выполнения условия, нет инструкций GOTO, DO или FOR для управления потоком выполнения. Инструкции SQL описывают, как организован набор данных или какие данные должны быть
выбраны или добавлены в базу данных. Последовательность шагов для решения этих задач определяется самой СУБД.
Наконец, SQL — это слабо структурированный язык, особенно по сравнению с такими высокоструктурированными языками, как С, Pascal или Java. Инструкции SQL напоминают обычные предложения естественного языка и содержат «слова-пустышки», не влияющие на смысл инструкции, но облегчающие ее чтение. В SQL почти нет нелогичностей, к тому же имеется ряд специальных правил, предотвращающих создание инструкций, которые выглядят как абсолютно правильные, но не имеют смысла.
Несмотря на не совсем точное название, SQL на сегодняшний день является стандартом языка для работы с реляционными базами данных. SQL — это достаточно мощный и в то же время относительно легкий для изучения язык. Краткое введение в SQL, представленное в следующей главе, познакомит вас с основными возможностями этого языка.
Роль SQL
Сам по себе SQL не является ни системой управления базами данных, ни отдельным программным продуктом. Приобрести SQL нельзя ни в магазине, ни на сайте. SQL — это неотъемлемая часть СУБД, язык и инструмент для связи с ней. На рис. 2. показаны некоторые компоненты типичной СУБД и как SQL объединяет их в единое целое.
Сердцем СУБД является механизм базы данных (database engine, часто называемый просто движком); он отвечает за структурирование данных, сохранение и получение их из базы данных. Он принимает SQL-запросы от других компонентов СУБД (таких, как генератор отчетов или модуль запросов), от пользовательских приложений и даже от других вычислительных систем. Как видно из рисунка, SQL выполняет много различных функций.
- SQL — интерактивный язык запросов. Для получения данных и вывода их на экран пользователи вводят команды SQL в интерактивных программах. Это удобный способ выполнения специальных запросов.
- SQL — язык программирования баз данных. Чтобы получить доступ к базе данных, программисты вставляют в свои прикладные программы команды SQL. Эта методика используется как в программах, написанных пользователями, так и в служебных программах баз данных (например, в таких, как генераторы отчетов).
- SQL — язык администрирования баз данных. Администратор базы данных, находящейся на рабочей станции или на сервере, использует SQL для определения структуры базы данных и управления доступом к данным.
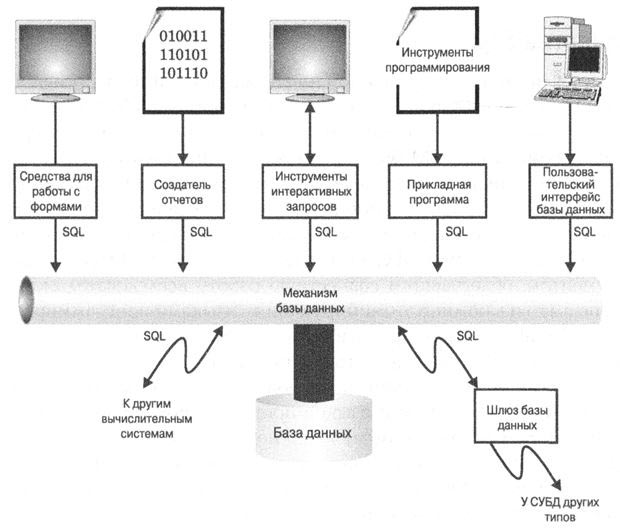
Рис. 2. Компоненты типичной системы управления базой данных
- SQL — язык создания приложений «клиент/сервер». В программах для персональных компьютеров SQL используется как средство организации связи по сети с серверами баз данных, в которых хранятся совместно используемые данные. Архитектура «клиент/сервер» используется во многих популярных приложениях корпоративного уровня.
- SQL — язык доступа к данным в Интернете. Веб-серверы Интернета, взаимодействующие с корпоративными данными и серверами приложений Интернета, используют SQL в качестве стандартного языка доступа к корпоративным базам данных, зачастую путем внедрения SQL-доступа в популярные языки сценариев наподобие Perl или РНР.
- SQL — язык распределенных баз данных. В системах управления распределенными базами данных SQL помогает распределять данные между несколькими соединенными вычислительными системами. Программное обеспечение каждой системы посредством SQL связывается с другими системами, посылая им запросы на доступ к данным.
- SQL — язык шлюзов баз данных. В вычислительных сетях с различными СУБД SQL часто используется в шлюзовой программе, которая позволяет СУБД одного типа связываться с СУБД другого типа.
Таким образом, SQL — полезный и мощный инструмент, обеспечивающий пользователям, программам и вычислительным системам доступ к информации, содержащейся в реляционных базах данных.
Преимущества SQL
SQL является чрезвычайно успешной информационной технологией. Вспомните, каким был рынок компьютеров в средине 1980-х годов, когда SQL только начинался. Тогда доминировали корпоративные мэйнфреймы и мини-компьютеры. Первый персональный компьютер IBM был создан всего лишь несколько лет назад, а его пользовательским интерфейсом была командная строка MS DOS. Мэйнфреймы IBM работали под управлением операционных систем от Digital Equipment, Data General, Hewlett-Packard и др. Компьютеры соединялись друг с другом при помощи закрытых сетей типа IBM SNA или DECnet от Digital Equipment. Интернет был не более чем инструментом, облегчавшим совместную работу исследовательских лабораторий, а веба не было и в помине. Доминирующими языками программирования были COBOL, С и Pascal; объектно-ориентированное программирование только-только делало первые шаги, a Java еще предстояло изобрести.
Во всех областях информационных технологий — от аппаратного обеспечения до операционных систем, сетей и языков программирования — ключевые технологии средины 1980-х годов уступили место новым решениям и методам. Но в мире управления данными реляционные базы данных и SQL никому не уступили свое место под солнцем. Они развивались, чтобы соответствовать новому аппаратному и программному обеспечению, операционным системам, сетям и языкам программирования. Несмотря на массу попыток свергнуть их с престола, реляционная модель и SQL преуспевают и остаются единственной доминирующей силой в области управления данными. Вот некоторые основные свойства SQL, обеспечивающие такой небывалый его успех в течение последних десятилетий.
- Независимость от конкретных СУБД
- Межплатформенная переносимость
- Наличие стандартов
- Поддержка со стороны компании IBM
- Поддержка со стороны компании Microsoft
- Построение на реляционной модели
- Высокоуровневая структура, напоминающая естественный язык
- Возможность выполнения специальных интерактивных запросов
- Обеспечение программного доступа к базам данных
- Возможность различного представления данных
- Полноценность в качестве языка, предназначенного для работы с базами данных
- Возможность динамического определения данных
- Поддержка архитектуры клиенг/сервер
- Поддержка приложений уровня предприятия
- Расширяемость и поддержка объектно-ориентированных технологий
- Возможность доступа к данным в Интернете
- Интеграция с языком Java (протокол JDBC)
- Поддержка открытого кода
- Промышленная инфраструктура
Ниже эти факторы рассмотрены более подробно.
Независимость от конкретных СУБД
Все ведущие поставщики СУБД используют SQL, и в течение последнего десятилетия ни одна новая СУБД, не поддерживающая SQL, не может рассчитывать на успех. Реляционную базу данных и программы, которые с ней работают, можно перенести с одной СУБД на другую с минимальными доработками и переподготовкой персонала. Программные средства, входящие в состав СУБД для персональных компьютеров, такие как программы для создания запросов, генераторы отчетов и генераторы приложений, работают с реляционными базами данных многих типов. Таким образом, SQL обеспечивает независимость от конкретных СУБД, что является одной из наиболее важных причин его популярности.
Межплатформенная переносимость
Реляционные СУБД выполняются на различных вычислительных системах — от мэйнфреймов и систем среднего уровня до персональных компьютеров, рабочих станций и переносных ПК. Они функционируют на отдельных компьютерах, в локальных и корпоративных сетях и даже на уровне Интернета. Приложения, созданные с помощью SQL и рассчитанные на однопользовательские системы, по мере своего развития могут быть перенесены на более крупные системы. Информация из корпоративных реляционных баз данных может быть загружена в базы данных отдельных подразделений или в персональные базы данных пользователей. Наконец, экономичные персональные компьютеры могут использоваться для тестирования прототипа приложения базы данных с использованием SQL, перед тем как перенести его на дорогую многопользовательскую систему.
Стандарты языка SQL
Официальный стандарт языка SQL был опубликован Американским национальным институтом стандартов (American National Standards Institute, ANSI) и Международной организацией по стандартизации (International Standards Organization, ISO) в 1986 году, после чего был расширен в 1989 году, а затем— в 1992, 1999, 2003 и 2006 годах. Кроме того, SQL является федеральным стандартом США в области обработки информации (Federal Information Processing Standard, FIPS), и, следовательно, соответствие ему является одним из основных требований, содержащихся в больших правительственных контрактах на разработки в компьютерной промышленности. В течение многих лет свой вклад в стандартизацию различных составляющих SQL, таких как интерфейсы программирования и объектно-ориентированные расширения, вносили многие международные, правительственные и промышленные группы. Со временем часть подобных инициатив стала составной частью стандарта ANSI/ISO. Все эти стандарты служат как бы официальной печатью, одобряющей SQL, и они ускорили завоевание им рынка.
Поддержка со стороны IBM
Изначально SQL разрабатывался исследователями IBM и быстро стал стратегическим продуктом, подтверждением чему служит флагманская СУБД DB2 компании IBM. Поддержка SQL имеется для всех основных семейств компьютеров компании IBM — от персональных компьютеров до мощных мэйнфреймов. Работа IBM ясно указала направление развития для других поставщиков баз данных и программных систем. Позже поддержка IBM существенно ускорила принятие SQL рынком. В 1970-х годах IBM была доминирующей силой на рынке вычислительной техники, так что ее поддержку SQL трудно переоценить.
Поддержка со стороны Microsoft
Компания Microsoft рассматривает подсистему доступа к базам данных как ключевую часть архитектуры Windows для персональных компьютеров. Как настольная, так и серверная версия Windows предоставляет стандартизованный доступ к реляционным базам данных посредством ODBC (Open Database Connectivity, открытый доступ к базам данных), программного интерфейса, основанного на SQL. Протокол ODBC поддерживается наиболее распространенными приложениями Windows (электронными таблицами, текстовыми процессорами, базами данных и т.п.), разработанными как самой компанией Microsoft, так и другими ведущими поставщиками, а кроме того, все ведущие SQL-базы данных обеспечивают доступ посредством ODBC. Со временем Microsoft расширила поддержку ODBC более высокоуровневыми объектно-ориентированными надстройками, включая поддержку управления данными в .NET. Но все эти новые технологии всегда могут работать с реляционными базами данных на более низком уровне ODBC/SQL. Когда в конце 1980-х годов Microsoft начала предпринимать усилия по превращению Windows в жизнеспособную серверную операционную систему, она представила SQL Server в качестве новой собственной SQL-базы данных. SQL Server и сегодня является флагманским продуктом Microsoft и ключевым компонентом архитектуры Microsoft .NET для веб-служб.
Основанность на реляционной модели
SQL является языком реляционных баз данных, поэтому он стал популярным тогда, когда популярной стала реляционная модель представления данных. Табличная структура реляционной базы данных со строками и столбцами интуитивно понятна пользователям, поэтому язык SQL является простым и легким для изучения. Реляционная модель имеет солидный теоретический фундамент, послуживший основой для эволюции и реализации реляционных баз данных. На волне популярности, вызванной успехом реляционной модели, SQL стал, по сути, единственным языком для реляционных баз данных.
Высокоуровневая структура, напоминающая естественный язык
Инструкции SQL похожи на обычные предложения английского языка, что упрощает их изучение и понимание. Частично это обусловлено тем, что инструкции SQL описывают данные, которые необходимо получить, а не способ их поиска. Таблицы и столбцы в реляционной базе данных могут иметь длинные описательные имена. В результате большинство инструкций SQL означает именно то, что точно соответствует их именам, поэтому их можно читать как простые, естественные предложения.
Интерактивные запросы
SQL является языком интерактивных запросов, который обеспечивает пользователям немедленный доступ к данным. С помощью SQL пользователь может в интерактивном режиме получить ответы на самые сложные запросы в считанные минуты или секунды, тогда как программисту по требовались бы дни или недели, чтобы написать соответствующую программу. Из-за того что SQL допускает интерактивное формирование запросов, данные становятся более доступными и могуч’ помочь в принятии решений, делая их более обоснованными. Интерактивность SQL на ранних этапах его эволюции была важным преимуществом над нереляционными базами данных и позже осталась таковым по отношению к чисто объектно-ориентированным базам данных.
Программный доступ к базе данных
Программисты пользуются языком SQL при создании приложений, обращающихся к базам данных. Одни и те же инструкции SQL используются как для интерактивного, так и для программного доступа, поэтому части программ, содержащие обращения к базе данных, можно вначале тестировать в интерактивном режиме, а затем встраивать в программу. В традиционных базах данных для программного доступа используются одни программные средства, а для выполнения интерактивных запросов — другие, без какой-либо связи между этими двумя режимами доступа.
Различные представления данных
С помощью SQL создатель базы данных может сделать так, что различные пользователи базы данных будут видеть различные представления ее структуры и содержимого. Например, базу данных можно спроектировать таким образом, что каждый пользователь будет видеть только данные, относящиеся к его подразделению или торговому региону. Кроме того, данные из различных частей базы данных могут быть скомбинированы и представлены пользователю в виде одной простой таблицы. Следовательно, представления можно использовать для усиления защиты базы данных и ее настройки под конкретные требования отдельных пользователей.
Полноценный язык для работы с базами данных
Первоначально SQL был задуман как язык интерактивных запросов, но сейчас он вышел далеко за рамки выборки данных. SQL является полноценным, самосогласованным и логичным языком, предназначенным для создания базы данных, управления ее защитой, изменения ее содержимого, выборки данных и совместного их использования несколькими параллельно работающими пользователями. Концепции, освоенные при изучении одной части языка, могут затем применяться в других командах, что повышает производительность работы пользователей.
Динамическое определение данных
С помощью SQL можно динамически изменять и расширять структуру базы данных даже в то время, когда пользователи обращаются к ее содержимому. Это большое преимущество перед статическими языками определения данных, которые запрещают доступ к базе данных во время изменения ее структуры. Таким образом, SQL обеспечивает максимальную гибкость, так как дает базе данных возможность адаптироваться к изменяющимся требованиям, не прерывая работу приложения, выполняющегося в реальном масштабе времени.
Архитектура “клиент/сервер”
SQL — естественное средство для реализации приложений, использующих распределенную архитектуру «клиент/сервер». В этой роли SQL служит связующим звеном между клиентской системой, взаимодействующей с пользователем, и серверной системой, управляющей базой данных, позволяя каждой из них сосредоточиться на выполнении своих функций. Кроме того, SQL дает возможность персональным компьютерам функционировать в качестве клиентов по отношению к сетевым серверам или более крупным базам данных, установленным на мэйнфреймах; это позволяет получать доступ к корпоративным данным из приложений, работающих на персональных компьютерах.
Поддержка приложений уровня предприятия
Все крупные приложения уровня предприятия, поддерживающие ежедневную деятельность больших компаний и организаций, используют для хранения и организации информации SQL-базы данных. В 1990-х годах, в связи с так называемой «проблемой 2000 года», большие фирмы массово перешли от собственных доморощенных систем к приложениям от таких производителей, как SAP, Oracle, PeopleSoft, Siebel и др. Данные, обрабатываемые такими приложениями (заказы, продажи, клиенты, склады и т.п.), обычно имеют структурированный вид записей с полями, который легко преобразуется в формат строк и столбцов SQL. Создавая свои приложения на базе SQL-баз данных уровня предприятия, производители программного обеспечения избегают необходимости разрабатывать собственные системы управления данными и пользуются всеми преимуществами существующих инструментов и опытом программистов. Поскольку все основные приложения уровня предприятия для своей работы требуют SQL-базы данных, увеличение продаж таких приложений автоматически влечет повышение спроса на новое программное обеспечение баз данных.
Расширяемость и поддержка объектно-ориентированных технологий
Основным вызовом доминированию языка SQL в качестве стандарта баз данных стало появление объектно-ориентированного программирования и языков программирования наподобие Java и C++. Как следствие общей направленности компьютерного рынка в сторону объектно-ориентированных технологий, появились объектные базы данных. В ответ на это поставщики реляционных СУБД начали постепенно расширять и модернизировать SQL, добавляя в него различные обьектные возможности. Появившиеся в результате »объектно-реляционные» базы данных, основанные, как и ранее, на SQL, стали более популярной альтернативой «чисто объектным» базам данных, обеспечив тем самым дальнейшее доминирование SQL в течение последнего десятилетия. Новейшие веяния объектных технологий, воплотившиеся в XML и архитектурах веб-служб, вновь «покусились» на доминирование SQL посредством «XML- баз данных» и альтернативных языков запросов в начале 2000-х годов. И вновь ведущие производители сумели отреагировать на угрозу путем добавления в язык XML- расширений. Пока что история SQL дает основания надеяться, что так же будут преодолены и новые вызовы, которые могут появиться в будущем.
Возможность доступа к данным в Интернете
Рост популярности Интернета и Веб привел к тому, что к концу 1990-х годов SQL стал рассматриваться и как стандартный язык для доступа к данным в Интернете. Первоначально, в эпоху зарождения веб, разработчики, занимавшиеся отображением на веб-страницах информации, извлеченной из баз данных, применяли SQL как средство взаимодействия со шлюзами баз данных. Позднее, с появлением трехуровневой архитектуры Интернета с четким разделением на тонкие клиенты, серверы приложений и серверы баз данных, SQL стал связующим звеном между вторым и третьим уровнями. Роль SQL в многоуровневой архитектуре в настоящее время начинает выходить за рамки серверных баз данных и включает кеширование и управление данными в реальном времени на уровне приложений или вблизи него.
Интеграция с языком Java (протокол JDBC)
Основной областью разработки SQL в последние пять-десять лет являлась интеграция SQL с Java. Осознав необходимость связи языка программирования Java с существующими реляционными базами данных, Sun Microsystems (создатель Java) предложил интерфейс JDBC (Java Database Connectivity), стандартный интерфейс прикладного программирования, позволяющий программистам на Java пользоваться SQL для обращения к базам данных. JDBC получил дальнейшую поддержку, когда был принят в качестве стандарта доступа к данным в спецификации Java2 Enterprise Edition (J2EE), которая определяет операционную среду, предоставляемую большинством ведущих серверов приложений Интернета. В дополнение к роли Java в качестве языка программирования, имеющего доступ к базам данных, многие ведущие производители реализовали поддержку Java в своих системах баз данных, тем самым обеспечив применение Java в качестве языка хранимых процедур и бизнес-логики в самих базах данных. Такая тенденция интеграции Java и SQL обеспечивает важность SQL и в новую эру Java-программирования.
Поддержка открытого кода
Одним из новейших важных событий в компьютерной индустрии стало применение подхода «открытого кода» в построении сложных программных систем. При этом подходе исходный текст является открытым и доступным бесплатно, так что многие программисты могут вносить в него свой вклад, добавлять в него новые возможности, исправлять ошибки, улучшать функциональность и т.п. Такое сообщество программистов, которые могут работать в различных организациях по всему миру, при определенной координации становится мощным двигателем новой технологии. Программное обеспечение с открытым кодом обычно доступно по невысокой цене (или вовсе бесплатно), что только добавляет ему привлекательности. В течение последнего десятилетия разработан ряд успешных проектов SQL- баз данных с открытым кодом, одна из которых, MySQL, стала стандартным компонентом набора программного обеспечения с открытым кодом LAMP, в который, кроме MySQL, входят операционная система Linux, веб-сервер Apache и язык сценариев РНР. Широкая доступность бесплатных SQL-баз данных с открытым кодом способствует дальнейшему росту популярности SQL.
Промышленная инфраструктура
Пожалуй, наиболее важным фактором растущей популярности SQL можно считать появление целой промышленной инфраструктуры, основанной на SQL. СУРБД на базе SQL являются важной частью этой инфраструктуры. Еще одной важной частью являются приложения уровня предприятия, использующие SQL и требующие наличия SQL-базы данных. Кроме того, можно упомянуть массу инструментов, таких как генераторы отчетов, инструменты для ввода данных, проектирования баз данных, программный инструментарий и многое другое, что облегчает применение SQL. Критической частью этой инфраструктуры является большое количество опытных программистов SQL. Еще одной важной частью является легкодоступное обучение и помощь при работе с SQL. Целые фирмы специализируются на консультировании по вопросам SQL, оптимизации и повышении производительности кода. Все эти части усиливают друг друга и обеспечивают успех SQL. Проще говоря, при наличии задач управления данными простейшие, наименее рискованные и наиболее дешевые решения получаются при применении SQL.
Давайте теперь поговорим, как работать с SQL? Рассмотрим синтаксис языка, основные операторы и команды.
SQL простыми словами
На основе материалов спикеров курса “SQL с 0 для анализа данных” собрали все, что нужно знать об SQL на первых порах. Привели реальные кейсы использования языка запросов и показали, как написать ваш первый код.
SQL, или Structured Query Language, — это язык структурированных запросов, использующийся для работы с базой данных: извлечения, обновления, добавления и удаления информации из нее. То есть, SQL — язык запросов для “общения” с данными.
Представить можно так:
Только вместо всем нам понятной фразы “принеси чай” используется особый синтаксис, другой язык. При работе с данными, как и при разговоре с представителем другой страны, вы будете использовать язык, понятный собеседнику, в нашем случае — компьютеру:
Знание SQL часто требуют не только от аналитиков, но и от продактов, проджектов и даже маркетологов. И не зря, ведь у языка структурированных запросов действительно масса возможностей.
- Извлечение данных
С помощью SQL вы работаете с данными, которые уже собирает ваша компания. Например, у сервиса ЯндексТакси есть данные по поездкам, таксистам, пользователям, работе службы поддержки и так далее. Так, с помощью SQL можно извлечь информацию по всем поездкам в Москве в промежуток с 18 до 19 часов для анализа спроса в час-пик.
- Изменение данных
К примеру, изменить имена всех пользователей “Татьяна” на “Марина”. Если представить более реалистичный кейс — можно исключить из базы данных пользователей, которые попали в нее по ошибке.
- Добавление данных
SQL позволяет объединять базы данных, выгружать скачанные БД (например, какую-то информацию от ваших конкурентов) для дальнейшего анализа.
- Валидация данных
Например, отчеты других аналитических систем, использующиеся в других отделах, могут не вызывать доверия из-за подозрительных скачков (просело количество посещений сайта, резко уменьшились клики и тд). С помощью SQL можно быстро сделать запрос в источник данных и проверить, так ли плоха ситуация.
- Скорость
Как уже упоминали, SQL полезен не только аналитикам. Представим, что вы продакт, вам необходимо быстро проверить новую гипотезу, а для этой задачи без данных не обойтись. Гораздо быстрее постановки ТЗ и согласования с аналитиками.
Примеры использования SQL:
- Онлайн-магазин: посчитать количество покупателей из Самары за предыдущий год
- Видео-платформа: найти топ-10 фильмов, у которых было больше всего просмотров за 2020 год в категории “комедии”
- Маркетинг: найти email пользователей, которые совершили покупку после нажатия на кнопку в рассылке
- Игры: определить, на каких уровнях игры пользователи тратят больше всего времени и после каких перестают заходить в приложение
Зачастую функционала GoogleAnalitics, YandexMetrics, Excel и Tableau бывает недостаточно из-за слишком большого объема данных, долгой настройки или сложных экспериментов. Поэтому большинство компаний и используют SQL.
Систем управления базами данных (СУБД) несколько, например, MySQL, Oracle, SQLServer или PostgreSQL. На курсе “SQL с 0 для анализа данных” Анна Атласова, бизнес-аналитик из Amazon, для начала советует попрактиковаться на web-версии SQLite.
Как и любой язык, SQL имеет определенные слова, которые выстраиваются в предложения, или команды. Рассмотрим пару базовых SQL-запросов на примере данных.
Открываем SQLite, загружаем базу данных.
В примере будем использовать БД Airbnb, сервиса для аренды жилья, ее мы даем на курсе (делимся лайфхаком: если уже оставляли заявку, попросите своего менеджера дать демо-доступ к нашей платформе, сможете попрактиковаться на этой базе данных). Открываем, слева появляются таблицы “hosts” и “listings”, то есть владельцы и информация о самом жилье (квартиры/дома/комнаты и тд).
Пришло время сделать первый запрос.
Чтобы посмотреть на всю таблицу целиком, запрашиваем (SELECT) все данные (*) из (FROM) таблицы владельцев (hosts). Получаем нашу таблицу под блоком ввода кода.
На скриншоте выше, видно, например, что Анна с id 43984 является владельцем жилья в Ирландии на Airbnb с 7 октября 2009 года. “F” в последнем столбце означает, что девушка не явлется супер-хостом (особый статус на сервисе), то есть значение в столбце = false.
Чтобы выдало конкретные столбцы, вместо * прописываем их названия.
SELECT Name, Location
Так мы получим таблицу из 2х столбцов: имени и местоположения.
SELECT что мы хотим (столбец/-цы) FROM откуда мы хотим (таблица)
Чтобы ограничить строки, используем LIMIT число. Например, LIMIT 3, тогда в нашей таблице появятся только 3 строки.
При написании запроса важно учитывать тип данных, который содержится в таблице. Например, это может быть число, текст и дата.
- Для вывода числа будет достаточно использовать сами числа. Например:
- Для текста используем кавычки:
WHERE name = ‘Anna’
- Для даты — формат “год-месяц-число”
WHERE host_since = ‘2009-10-07’
Оператор WHERE задает условие, то есть, например, “Я хочу вывести все данные из таблицы с владельцами жилья, у кого id соответствует 43984” (скорее всего результат получим один, обычно id не повторяются) или “Я хочу вывести все данные владельцев, кого зовут Анна” (здесь уже не факт, что результат будет единственным).
С оператором WHERE также можно использовать знаки больше или меньше: “<”, “>”, они, например, позволяют отфильтровать владельцев жилья, попавших в БД после определенной даты. Сделать это можно так: WHERE host_since > ‘2010-01-01’. В таблице получим всех хостов, присоединившихся к Airbnb после 1 января 2010.
С некоторыми ключевыми словами мы уже познакомились, поэтому обратим внимание на важную особенность работу SQL — все ключевые слова и операторы должны иметь определенный порядок:
- SELECT
- FROM
- WHERE
- GROUP BY
- HAVING
- ORDER BY
- LIMIT
При нарушении порядка, SQL запутается и перестанет вас понимать 🙁
Важно еще отметить, что SELECT и FROM — ключевые слова, остальные — опциональные, поэтому использовать WHERE или другие операторы без SELECT FROM не получится.
Памятка/шпаргалка по SQL

Изучение настоящей шпаргалки не сделает вас мастером SQL, но позволит получить общее представление об этом языке программирования и возможностях, которые он предоставляет. Рассматриваемые в шпаргалке возможности являются общими для всех или большинства диалектов SQL.
Для более полного погружения в SQL рекомендую изучить эти руководства по MySQL и PostgreSQL от Метанита. Они хороши тем, что просты в изучении и позволяют быстро начать работу с названными СУБД.
При обнаружении ошибок, опечаток и неточностей, не стесняйтесь писать мне в личку.
Содержание
Что такое SQL?
SQL — это язык структурированных запросов (Structured Query Language), позволяющий хранить, манипулировать и извлекать данные из реляционных баз данных (далее — РБД, БД).
Почему SQL?
- получать доступ к данным в системах управления РБД
- описывать данные (их структуру)
- определять данные в БД и управлять ими
- взаимодействовать с другими языками через модули SQL, библиотеки и предваритальные компиляторы
- создавать и удалять БД и таблицы
- создавать представления, хранимые процедуры (stored procedures) и функции в БД
- устанавливать разрешения на доступ к таблицам, процедурам и представлениям
Процесс SQL
При выполнении любой SQL-команды в любой RDBMS (Relational Database Management System — система управления РБД, СУБД, например, PostgreSQL, MySQL, MSSQL, SQLite и др.) система определяет наилучший способ выполнения запроса, а движок SQL определяет способ интерпретации задачи.
В данном процессе участвует несколького компонентов:
- диспетчер запросов (Query Dispatcher)
- движок оптимизации (Optimization Engines)
- классический движок запросов (Classic Query Engine)
- движок запросов SQL (SQL Query Engine) и т.д.
Классический движок обрабатывает все не-SQL-запросы, а движок SQL-запросов не обрабатывает логические файлы.
Команды SQL
Стандартными командами для взаимодействия с РБД являются CREATE , SELECT , INSERT , UPDATE , DELETE и DROP . Эти команды могут быть классифицированы следующим образом:
- DDL — язык определения данных (Data Definition Language)
| N | Команда | Описание |
|---|---|---|
| 1 | CREATE | Создает новую таблицу, представление таблицы или другой объект в БД |
| 2 | ALTER | Модифицирует существующий в БД объект, такой как таблица |
| 3 | DROP | Удаляет существующую таблицу, представление таблицы или другой объект в БД |
- DML — язык изменения данных (Data Manipulation Language)
| N | Команда | Описание |
|---|---|---|
| 1 | SELECT | Извлекает записи из одной или нескольких таблиц |
| 2 | INSERT | Создает записи |
| 3 | UPDATE | Модифицирует записи |
| 4 | DELETE | Удаляет записи |
- DCL — язык управления данными (Data Control Language)
| N | Команда | Описание |
|---|---|---|
| 1 | GRANT | Наделяет пользователя правами |
| 1 | REVOKE | Отменяет права пользователя |
Обратите внимание: использование верхнего регистра в названиях команд SQL — это всего лишь соглашение, большинство СУБД нечувствительны к регистру. Тем не менее, форма записи инструкций, когда названия команд пишутся большими буквами, а названия таблиц, колонок и др. — маленькими, позволяет быстро определять назначение производимой с данными операции.
Что такое таблица?
Данные в СУБД хранятся в объектах БД, называемых таблицами (tables). Таблица, как правило, представляет собой коллекцию связанных между собой данных и состоит из определенного количества колонок и строк.
Таблица — это самая распространенная и простая форма хранения данных в РБД. Вот пример таблицы с пользователями (users):
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 25 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
| 4 | Oleg | 28 | Moscow | inactive |
Что такое поле?
Каждая таблица состоит из небольших частей — полей (fields). Полями в таблице users являются userId, userName, age, city и status. Поле — это колонка таблицы, предназначенная для хранения определенной информации о каждой записи в таблице.
Обратите внимание: вместо userId и userName можно было бы использовать id и name , соответственно. Но при работе с несколькими объектами, содержащими свойство id , бывает сложно понять, какому объекту принадлежит идентификатор, особенно, если вы, как и я, часто прибегаете к деструктуризации. Что касается слова name , то оно часто оказывается зарезервизованным, т.е. уже используется в среде, в которой выполняется код, поэтому я стараюсь его не использовать.
Что такое запись или строка?
Запись или строка (record/row) — это любое единичное вхождение (entry), существующее в таблице. В таблице users 5 записей. Проще говоря, запись — это горизонтальное вхождение в таблице.
Что такое колонка?
Колонка (column) — это вертикальное вхождение в таблице, содержащее всю информацию, связанную с определенным полем. В таблице users одной из колонок является city , которая содержит названия городов, в которых проживают пользователи.
Что такое нулевое значение?
Нулевое значение (NULL) — это значение поля, которое является пустым, т.е. нулевое значение — это значение поля, не имеющего значения. Важно понимать, что нулевое значение отличается от значения 0 и от значения поля, содержащего пробелы ( `). Поле с нулевым значением — это такое поля, которое осталось пустым при создании записи. Также, следует учитывать, что в некоторых СУБД пустая строка ( » ) — это NULL`, а в некоторых — это разные значения.
Ограничения
Ограничения (constraints) — это правила, применяемые к данным. Они используются для ограничения данных, которые могут быть записаны в таблицу. Это обеспечивает точность и достоверность данных в БД.
Ограничения могут устанавливаться как на уровне колонки, так и на уровне таблицы.
Среди наиболее распространенных ограничений можно назвать следующие:
- NOT NULL — колонка не может иметь нулевое значение
- DEFAULT — значение колонки по умолчанию
- UNIQUE — все значения колонки должны быть уникальными
- PRIMARY KEY — первичный или основной ключ, уникальный идентификатор записи в текущей таблице
- FOREIGN KEY — внешний ключ, уникальный идентификатор записи в другой таблице (таблице, связанной с текущей)
- CHECK — все значения в колонке должны удовлетворять определенному условию
- INDEX — быстрая запись и извлечение данных
Любое ограничение может быть удалено с помощью команды ALTER TABLE и DROP CONSTRAINT + название ограничения. Некоторые реализации предоставляют сокращения для удаления ограничений и возможность отключать ограничения вместо их удаления.
Целостность данных
В каждой СУБД существуют следующие категории целостности данных:
- целостность объекта (Entity Integrity) — в таблице не должно быть дубликатов (двух и более строк с одинаковыми значениями)
- целостность домена (Domain Integrity) — фильтрация значений по типу, формату или диапазону
- целостность ссылок (Referential integrity) — строки, используемые другими записями (строки, на которые в других записях имеются ссылки), не могут быть удалены
- целостность, определенная пользователем (User-Defined Integrity) — дополнительные правила
Нормализация БД
Нормализация — это процесс эффективной организации данных в БД. Существует две главных причины, обуславливающих необходимость нормализации:
- предотвращение записи в БД лишних данных, например, хранения одинаковых данных в разных таблицах
- обеспечение "оправданной" связи между данными
Нормализация предполагает соблюдение нескольких форм. Форма — это формат структурирования БД. Существует три главных формы: первая, вторая и, соответственно, третья. Я не буду вдаваться в подробности об этих формах, при желании, вы без труда найдете необходимую информацию.
Синтаксис SQL
Синтаксис — это уникальный набор правил и рекомендаций. Все инструкции SQL должны начинаться с ключевого слова, такого как SELECT , INSERT , UPDATE , DELETE , ALTER , DROP , CREATE , USE , SHOW и т.п. и заканчиваться точкой с запятой ( ; ) (точка с запятой не входит в синтаксис SQL , но ее наличия, как правило, требуют консольные клиенты СУБД для обозначения окончания ввода команды). SQL не чувствителен к регистру, т.е. SELECT , select и SeLeCt являются идентичными инструкицями. Исключением из этого правила является MySQL , где учитывается регистр в названии таблицы.
Примеры синтаксиса
Типы данных
Каждая колонка, переменная и выражение в SQL имеют определенный тип данных (data type). Основные категории типов данных:
Точные числовые
| Тип данных | От | До |
|---|---|---|
| bigint | -9,223,372,036,854,775,808 | 9,223,372,036,854,775,807 |
| int | -2,147,483,648 | 2,147,483,647 |
| smallint | -32,768 | 32,767 |
| tinyint | 0 | 255 |
| bit | 0 | 1 |
| decimal | -10^38 +1 | 10^38 -1 |
| numeric | -10^38 +1 | 10^38 -1 |
| money | -922,337,203,685,477.5808 | +922,337,203,685,477.5807 |
| smallmoney | -214,748.3648 | +214,748.3647 |
Приблизительные числовые
| Тип данных | От | До |
|---|---|---|
| float | -1.79E + 308 | 1.79E + 308 |
| real | -3.40E + 38 | 3.40E + 38 |
Дата и время
| Тип данных | От | До |
|---|---|---|
| datetime | Jan 1, 1753 | Dec 31, 9999 |
| smalldatetime | Jan 1, 1900 | Jun 6, 2079 |
| date | Дата сохраняется в виде June 30, 1991 | |
| time | Время сохраняется в виде 12:30 P.M. |
Строковые символьные
| N | Тип данных | Описание |
|---|---|---|
| 1 | char | Строка длиной до 8,000 символов (не-юникод символы, фиксированной длины) |
| 2 | varchar | Строка длиной до 8,000 символов (не-юникод символы, переменной длины) |
| 3 | text | Не-юникод данные переменной длины, длиной до 2,147,483,647 символов |
Строковые символьные (юникод)
| N | Тип данных | Описание |
|---|---|---|
| 1 | nchar | Строка длиной до 4,000 символов (юникод символы, фиксированной длины) |
| 2 | nvarchar | Строка длиной до 4,000 символов (юникод символы, переменной длины) |
| 3 | ntext | Юникод данные переменной длины, длиной до 1,073,741,823 символов |
Бинарные
| N | Тип данных | Описание |
|---|---|---|
| 1 | binary | Данные размером до 8,000 байт (фиксированной длины) |
| 2 | varbinary | Данные размером до 8,000 байт (переменной длины) |
| 3 | image | Данные размером до 2,147,483,647 байт (переменной длины) |
Смешанные
| N | Тип данных | Описание |
|---|---|---|
| 1 | timestamp | Уникальные числа, обновляющиеся при каждом изменении строки |
| 2 | uniqueidentifier | Глобально-уникальный идентификатор (GUID) |
| 3 | cursor | Объект курсора |
| 4 | table | Промежуточный результат, предназначенный для дальнейшей обработки |
Операторы
Оператор (operators) — это ключевое слово или символ, которые, в основном, используются в инструкциях WHERE для выполнения каких-либо операций. Они используются как для определения условий, так и для объединения нескольких условий в инструкции.
В дальнейших примерах мы будем исходить из предположения, что переменная a имеет значение 10 , а b — 20 .
Арифметические
| Оператор | Описание | Пример |
|---|---|---|
| + (сложение) | Сложение значений | a + b = 30 |
| — (вычитание) | Вычитание правого операнда из левого | b — a = 10 |
| * (умножение) | Умножение значений | a * b = 200 |
| / (деление) | Деление левого операнда на правый | b / a = 2 |
| % (деление с остатком/по модулю) | Деление левого операнда на правый с остатком (возвращается остаток) | b % a = 0 |
Операторы сравнения
| Оператор | Описание | Пример |
|---|---|---|
| = | Определяет равенство значений | a = b -> false |
| != | Определяет НЕравенство значений | a != b -> true |
| <> | Определяет НЕравенство значений | a <> b -> true |
| > | Значение левого операнда больше значения правого операнда? | a > b -> false |
| < | Значение левого операнда меньше значения правого операнда? | a < b -> true |
| >= | Значение левого операнда больше или равно значению правого операнда? | a >= b -> false |
| <= | Значение левого операнда меньше или равно значению правого операнда? | a <= b -> true |
| !< | Значение левого операнда НЕ меньше значения правого операнда? | a !< b -> false |
| !> | Значение левого операнда НЕ больше значения правого операнда? | a !> b -> true |
Логические операторы
| N | Оператор | Описание |
|---|---|---|
| 1 | ALL | Сравнивает все значения |
| 2 | AND | Объединяет условия (все условия должны совпадать) |
| 3 | ANY | Сравнивает одно значение с другим, если последнее совпадает с условием |
| 4 | BETWEEN | Проверяет вхождение значения в диапазон от минимального до максимального |
| 5 | EXISTS | Определяет наличие строки, соответствующей определенному критерию |
| 6 | IN | Выполняет поиск значения в списке значений |
| 7 | LIKE | Сравнивает значение с похожими с помощью операторов подстановки |
| 8 | NOT | Инвертирует (меняет на противоположное) смысл других логических операторов, например, NOT EXISTS, NOT IN и т.д. |
| 9 | OR | Комбинирует условия (одно из условий должно совпадать) |
| 10 | IS NULL | Определяет, является ли значение нулевым |
| 11 | UNIQUE | Определяет уникальность строки |
Выражения
Выражение (expression) — это комбинация значений, операторов и функций для оценки (вычисления) значения. Выражения похожи на формулы, написанные на языке запросов. Они могут использоваться для извлечения из БД определенного набора данных.
Базовый синтаксис выражения выглядит так:
Существуют различные типы выражений: логические, числовые и выражения для работы с датами.
Логические
Логические выражения извлекают данные на основе совпадения с единичным значением.
Предположим, что в таблице users имеются следующие записи:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 25 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
| 4 | Oleg | 28 | Moscow | inactive |
Выполняем поиск активных пользователей:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 25 | Moscow | active |
| 3 | Elena | 27 | Ekaterinburg | active |
Числовые
Используются для выполнения арифметических операций в запросе.
Простой пример использования числового выражения:
| addition |
|---|
| 15 |
Существует несколько встроенных функций, таких как count() , sum() , avg() , min() , max() и др. для выполнения так называемых агрегирующих вычислений данных таблицы или колонки.
| records |
|---|
| 4 |
- AVG — вычисляет среднее значение
- SUM — вычисляет сумму значений
- MIN — вычисляет наименьшее значение
- MAX — вычисляет наибольшее значение
- COUNT — вычисляет количество записей в таблице
Также существует несколько встроенных функций для работы со строками:
- CONCAT — объединение строк
- LENGTH — возвращает количество символов в строке
- TRIM — удаляет пробелы в начале и конце строки
- SUBSTRING — извлекает подстроку из строки
- REPLACE — заменяет подстроку в строке
- LOWER — переводит символы строки в нижний регистр
- UPPER — переводит символы строки в верхний регистр и т.д.
- ROUND — округляет число
- TRUNCATE — обрезает дробное число до указанного количества знаков после запятой
- CEILING — возвращает наименьшее целое число, которое больше или равно текущему значению
- FLOOR — возвращает наибольшее целое число, которое меньше или равно текущему значению
- POWER — возводит число в указанную степень
- SQRT — возвращает квадратный корень числа
- RAND — генерирует случайное число с плавающей точкой в диапазоне от 0 до 1
Выражения для работы с датами
Эти выражения, как правило, возвращают текущую дату и время.
| Current_Timestamp |
|---|
| 2021-06-20 12:45:00 |
CURRENT_TIMESTAMP — это и выражение, и функция ( CURRENT_TIMESTAMP() ). Другая функция для получения текущей даты и времени — NOW() .
Другие функции для получения текущей даты и времени:
- CURDATE / CURRENT_DATE — возвращает текущую дату
- CURTIME / CURRENT_TIME — возвращает текущее время и т.д.
Функции для разбора даты и времени:
- DAYOFMONTH(date) — возвращает день месяца в виде числа
- DAYOFWEEK(date) — возвращает день недели в виде числа
- DAYOFYEAR(date) — возвращает номер дня в году
- MONTH(date) — возвращает месяц
- YEAR(date) — возвращает год
- LAST_DAY(date) — возвращает последний день месяца в виде даты
- HOUR(time) — возвращает час
- MINUTE(time) — возвращает минуты
- SECOND(time) — возвращает секунды и др.
Функции для манипулирования датами:
- DATE_ADD(date, interval) — выполняет сложение даты и определенного временного интервала
- DATE_SUB(date, interval) — выполняет вычитание из даты определенного временного интервала
- DATEDIFF(date1, date2) — возвращает разницу в днях между двумя датами
- TO_DAYS(date) — возвращает количество дней с 0-го дня года
- TIME_TO_SEC(time) — возвращает количество секунд с полуночи и др.
Для форматирования даты и времени используются функции DATE_FORMAT(date, format) и TIME_FORMAT(date, format) , соответственно.
Создание БД
Для создания БД используется инструкция CREATE DATABASE .
Условие IF NOT EXISTS позволяет избежать получения ошибки при попытке создания БД, которая уже существует.
Название БД должно быть уникальным в пределах СУБД.
Создаем БД testDB :
Получаем список БД:
| Database |
|---|
| information_schema |
| postgres |
| testDB |
Удаление БД
Для удаления БД используется инструкция DROP DATABASE .
Условие IF EXISTS позволяет избежать получения ошибки при попытке удаления несуществующей БД.
Обратите внимание: при удалении БД уничтожаются все данные, которые в ней хранятся, так что будьте предельно внимательны при использовании данной команды.
Проверяем, что БД удалена:
Для получения списка таблиц используется инструкция SHOW TABLES .
| Database |
|---|
| information_schema |
| postgres |
Выбор БД
При наличии нескольких БД, перед выполнением каких-либо операций, необходимо выбрать БД. Для этого используется инструкция USE .
Предположим, что мы не удаляли testDB . Тогда мы можем выбрать ее так:
Создание таблицы
Создание таблицы предполагает указание названия таблицы и определение колонок таблицы и их типов данных. Для создания таблицы используется инструкция CREATE TABLE .
Для создания таблицы путем копирования другой таблицы используется сочетание CREATE TABLE и SELECT .
Пример создания таблицы users , где первичным ключом являются идентификаторы пользователей, а поля для имени и возраста пользователя не могут быть нулевыми:
Проверяем, что таблица была создана:
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| userId | int(11) | NO | PRI | ||
| userName | varchar(20) | NO | |||
| age | int(11) | NO | |||
| city | varchar(20) | NO | |||
| status | varchar(8) | YES | NULL |
Удаление таблицы
Для удаления таблицы используется инструкция DROP TABLE .
Обратите внимание: при удалении таблицы, навсегда удаляются все хранящиеся в ней данные, индексы, триггеры, ограничения и разрешения, так что будьте предельно внимательны при использовании данной команды.
Удаляем таблицу users :
Теперь, если мы попытаемся получить описание users , то получим ошибку:
Добавление колонок
Для добавления в таблицу колонок используется инструкция INSERT INTO .
Названия колонок можно не указывать, однако, в этом случае значения должны перечисляться в правильном порядке.
Во избежание ошибок, рекомендуется всегда перечислять названия колонок.
Предположим, что мы не удаляли таблицу users . Заполним ее пользователями:
В таблицу можно добавлять несколько строк за один раз.
Также, как было отмечено, при добавлении строки названия полей можно опускать:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 25 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
| 4 | Oleg | 28 | Moscow | inactive |
Заполнение таблицы с помощью другой таблицы
Выборка полей
Для выборки полей из таблицы используется инструкция SELECT . Она возвращает данные в виде результирующей таблицы (результирующего набора, result-set).
Для выборки всех полей используется такой синтаксис:
Произведем выборку полей userId , userName и age из таблицы users :
| userId | userName | age |
|---|---|---|
| 1 | Igor | 25 |
| 2 | Vika | 26 |
| 3 | Elena | 27 |
| 4 | Oleg | 28 |
Предложение WHERE
Предложение WHERE используется для фильтрации возвращаемых данных. Оно используется совместно с SELECT , UPDATE , DELETE и другими инструкциями.
Условие (condition), которому должны удовлетворять возвращаемые записи, определяется с помощью операторов сравнения или логических операторов типа > , < , = , NOT , LIKE и т.д.
Сделаем выборку полей userId , userName и age активных пользователей:
| userId | userName | age |
|---|---|---|
| 1 | Igor | 25 |
| 3 | Elena | 27 |
Сделаем выборку полей userId , age и city пользователя с именем Vika .
| userId | age | city |
|---|---|---|
| 2 | 26 | Ekaterinburg |
Обратите внимание: строки в предложении WHERE должны быть обернуты в одинарные кавычки ( » ), а числа, напротив, указываются как есть.
Операторы AND и OR
Конъюнктивный оператор AND и дизъюнктивный оператор OR используются для соединения нескольких условий при фильтрации данных.
AND
Возвращаемые записи должны удовлетворять всем указанным условиям.
Сделаем выборку полей userId , userName и age активных пользователей старше 26 лет:
| userId | userName | AGE |
|---|---|---|
| 3 | Elena | 27 |
OR
Возвращаемые записи должны удовлетворять хотя бы одному условию.
Сделаем выборку тех же полей неактивных пользователей или пользователей, младше 27 лет:
| userId | userName | age |
|---|---|---|
| 1 | Igor | 25 |
| 2 | Vika | 26 |
Обновление полей
Для обновления полей используется инструкция UPDATE . SET . Эта инструкция, обычно, используется в сочетании с предложением WHERE .
Обновим возраст пользователя с именем Igor :
Если в данном случае опустить WHERE , то будет обновлен возраст всех пользователей.
Удаление записей
Для удаления записей используется инструкция DELETE . Эта инструкция также, как правило, используется в сочетании с предложением WHERE .
Удалим неактивных пользователей:
Если в данном случае опустить WHERE , то из таблицы users будут удалены все записи.
Предложения LIKE и REGEX
LIKE
Предложение LIKE используется для сравнения значений с помощью операторов с подстановочными знаками. Существует два вида таких операторов:
- проценты ( % )
- нижнее подчеркивание ( _ )
% означает 0, 1 или более символов. _ означает точно 1 символ.
| N | Инструкция | Результат |
|---|---|---|
| 1 | WHERE col LIKE ‘foo%’ | Любые значения, начинающиеся с foo |
| 2 | WHERE col LIKE ‘%foo%’ | Любые значения, содержащие foo |
| 3 | WHERE col LIKE ‘_oo%’ | Любые значения, содержащие oo на второй и третьей позициях |
| 4 | WHERE col LIKE ‘f%%’ | Любые значения, начинающиеся с f и состоящие как минимум из 1 символа |
| 5 | WHERE col LIKE ‘%oo’ | Любые значения, оканчивающиеся на oo |
| 6 | WHERE col LIKE ‘_o%o’ | Любые значения, содержащие o на второй позиции и оканчивающиеся на o |
| 7 | WHERE col LIKE ‘f_o’ | Любые значения, содержащие f и o на первой и третьей позициях, соответственно, и состоящие из трех символов |
Сделаем выборку неактивных пользователей:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 4 | Oleg | 28 | Moscow | inactive |
Сделаем выборку пользователей 30 лет и старше:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 30 | Moscow | active |
REGEX
Предложение REGEX позволяет определять регулярное выражение, которому должна соответствовать запись.
В регулярное выражении могут использоваться следующие специальные символы:
- ^ — начало строки
- $ — конец строки
- . — любой символ
- [символы] — любой из указанных в скобках символов
- [начало-конец] — любой символ из диапазона
- | — разделяет шаблоны
Сделаем выборку пользователей с именами Igor и Vika :
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 30 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
Предложение TOP / LIMIT / ROWNUM
Данные предложения позволяют извлекать указанное количество или процент записей с начала таблицы. Разные СУБД поддерживают разные предложения.
Сделаем выборку первых трех пользователей:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 30 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
Параметр offset (смещение) определяет количество пропускаемых записей. Например, так можно извлечь первых двух пользователей, начиная с третьего:
Предложения ORDER BY и GROUP BY
ORDER BY
Предложение ORDER BY используется для сортировки данных по возрастанию ( ASC ) или убыванию ( DESC ). Многие СУБД по умолчанию выполняют сортировку по возрастанию.
Обратите внимание: колонки для сортировки должны быть указаны в списке колонок для выборки.
Сделаем выборку пользователей, отсортировав их по городу и возрасту:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
| 1 | Igor | 25 | Moscow | active |
| 4 | Oleg | 28 | Moscow | inactive |
Теперь выполним сортировку по убыванию:
Определим собственный порядок сортировки по убыванию:
GROUP BY
Предложение GROUP BY используется совместно с инструкцией SELECT для группировки записей. Оно указывается после WHERE и перед ORDER BY .
Сгруппируем активных пользователей по городам:
| city | amount |
|---|---|
| Ekaterinburg | 2 |
| Moscow | 2 |
Ключевое слово DISTINCT
Ключевое слово DISTINCT используется совместно с инструкцией SELECT для возврата только уникальных записей (без дубликатов).
Сделаем выборку городов проживания пользователей:
| city |
|---|
| Ekaterinburg |
| Moscow |
Соединения
Соединения (joins) используются для комбинации записей двух и более таблиц.
Предположим, что кроме users , у нас имеется таблица orders с заказами пользователей следующего содержания:
| orderId | date | userId | amount |
|---|---|---|---|
| 101 | 2021-06-21 00:00:00 | 2 | 3000 |
| 102 | 2021-06-20 00:00:00 | 2 | 1500 |
| 103 | 2021-06-19 00:00:00 | 3 | 2000 |
| 104 | 2021-06-18 00:00:00 | 3 | 1000 |
Сделаем выборку полей userId , userName , age и amount из наших таблиц посредством их соединения:
| userId | userName | age | amount |
|---|---|---|---|
| 2 | Vika | 26 | 3000 |
| 2 | Vika | 26 | 1500 |
| 3 | Elena | 27 | 2000 |
| 3 | Elena | 27 | 1000 |
При соединении таблиц могут использоваться такие операторы, как = , < , > , <> , <= , >= , != , BETWEEN , LIKE и NOT , однако наиболее распространенным является = .
Существуют разные типы объединений:
- INNER JOIN — возвращает записи, имеющиеся в обеих таблицах
- LEFT JOIN — возвращает записи из левой таблицы, даже если такие записи отсутствуют в правой таблице
- RIGHT JOIN — возвращает записи из правой таблицы, даже если такие записи отсутствуют в левой таблице
- FULL JOIN — возвращает все записи объединяемых таблиц
- CROSS JOIN — возвращает все возможные комбинации строк обеих таблиц
- SELF JOIN — используется для объединения таблицы с самой собой
Предложение UNION
Предложение/оператор UNION используется для комбинации результатов двух и более инструкций SELECT . При этом, возвращаются только уникальные записи.
В случае с UNION , каждая инструкция SELECT должна иметь:
- одинаковый набор колонок для выборки
- одинаковое количество выражений
- одинаковые типы данных колонок и
- одинаковый порядок колонок
Однако, они могут быть разной длины.
Объединим наши таблицы users и orders :
| userId | userName | amount | date |
|---|---|---|---|
| 1 | Igor | NULL | NULL |
| 2 | Vika | 3000 | 2021-06-21 00:00:00 |
| 2 | Vika | 1500 | 2021-06-20 00:00:00 |
| 3 | Elena | 2000 | 2021-06-19 00:00:00 |
| 3 | Elena | 1000 | 2021-06-18 00:00:00 |
| 4 | Alex | NULL | NULL |
Предложение UNION ALL
Предложение UNION ALL также используется для объединения результатов двух и более инструкций SELECT . При этом, возвращаются все записи, включая дубликаты.
Существует еще два предложения, похожих на UNION :
- INTERSECT — используется для комбинации результатов двух и более SELECT , но возвращаются только строки из первого SELECT , совпадающие со строками из второго SELECT
- EXCEPT|MINUS — возвращаются только строки из первого SELECT , отсутствующие во втором SELECT
Синонимы
Синонимы (aliases) позволяют временно изменять названия таблиц и колонок. "Временно" означает, что новое название используется только в текущем запросе, в БД название остается прежним.
Синтаксис синонима таблицы:
Синтаксис синонима колонки:
Пример использования синонимов таблиц:
| userId | userName | age | amount |
|---|---|---|---|
| 2 | Vika | 26 | 3000 |
| 2 | Vika | 26 | 1500 |
| 3 | Elena | 27 | 2000 |
| 3 | Elena | 27 | 1000 |
Пример использования синонимов колонок:
| user_id | user_name | user_age |
|---|---|---|
| 1 | Igor | 30 |
| 3 | Elena | 27 |
Индексы
Создание индексов
Индексы — это специальные поисковые таблицы (lookup tables), которые используются движком БД в целях более быстрого извлечения данных. Проще говоря, индекс — это указатель или ссылка на данные в таблице.
Индексы ускоряют работу инструкции SELECT и предложения WHERE , но замедляют работу инструкций UPDATE и INSERT . Индексы могут создаваться и удаляться, не оказывая никакого влияния на данные.
Для создания индекса используется инструкция CREATE INDEX , позволяющая определять название индекса, индексируемые колонки и порядок индексации (по возрастанию или по убыванию).
К индексам можно применять ограничение UNIQUE для того, чтобы обеспечить их уникальность.
Синтаксис создания индекса:
Синтаксис создания индекса для одной колонки:
Синтакис создания уникальных индексов (такие индексы используются не только для повышения производительности, но и для обеспечения согласованности данных):
Синтаксис создания индексов для нескольких колонок (композиционный индекс):
Решение о создании индексов для одной или нескольких колонок следует принимать на основе того, какие колонки будут часто использоваться в запросе WHERE в качестве условия для сортировки строк.
Для ограничений PRIMARY KEY и UNIQUE автоматически создаются неявные индексы.
Удаление индексов
Для удаления индексов используется инструкция DROP INDEX :
Несмотря на то, что индексы предназначены для повышения производительности БД, существуют ситуации, в которых их использования лучше избегать.
К таким ситуациям относится следующее:
- индексы не должны использоваться в маленьких таблицах
- в таблицах, которые часто и в большом объеме обновляются или перезаписываются
- в колонках, которые содержат большое количество нулевых значений
- в колонках, над которыми часто выполняются операции
Обновление таблицы
Команда ALTER TABLE используется для добавления, удаления и модификации колонок существующей таблицы. Также эта команда используется для добавления и удаления ограничений.
Добавляем в таблицу users новую колонку — пол пользователя:
Удаляем эту колонку:
Очистка таблицы
Команда TRUNCATE TABLE используется для очистки таблицы. Ее отличие от DROP TABLE состоит в том, что сохраняется структура таблицы ( DROP TABLE полностью удаляет таблицу и все ее данные).
Очищаем таблицу users :
Проверяем, что users пустая:
Представления
Представление (view) — это не что иное, как инструкция, записанная в БД под определенным названием. Другими словами, представление — это композиция таблицы в форме предварительно определенного запроса.
Представления могут содержать все или только некоторые строки таблицы. Представление может быть создано на основе одной или нескольких таблиц (это зависит от запроса для создания представления).
Представления — это виртутальные таблицы, позволяющие делать следующее:
- структурировать данные способом, который пользователи находят наиболее естественным или интуитивно понятным
- ограничивать доступ к данным таким образом, что пользователь может просматривать и (иногда) модифицировать только то, что ему нужно и ничего более
- объединять данные из нескольких таблиц для формирования отчетов
Создание представления
Для создания представления используется инструкция CREATE VIEW . Как было отмечено, представления могут создаваться на основе одной или нескольких таблиц, и даже на основе другого представления.
Создаем представление для имен и возраста пользователей:
Получаем данные с помощью представления:
| userName | age |
|---|---|
| Igor | 30 |
| Vika | 26 |
| Elena | 27 |
| Oleg | 28 |
WITH CHECK OPTION
WITH CHECK OPTION — это настройка инструкции CREATE VIEW . Она позволяет обеспечить соответствие всех UPDATE и INSERT условию, определенном в представлении.
Если условие не удовлетворяется, выбрасывается исключение.
Обновление представления
Представление может быть обновлено при соблюдении следующих условий:
- SELECT не содержит ключевого слова DISTINCT
- SELECT не содержит агрегирующих функций
- SELECT не содержит функций установки значений
- SELECT не содержит операций установки значений
- SELECT не содержит предложения ORDER BY
- FROM не содержит больше одной таблицы
- WHERE не содержит подзапросы
- запрос не содержит GROUP BY или HAVING
- вычисляемые колонки не обновляются
- все ненулевые колонки из базовой таблицы включены в представление в том же порядке, в каком они указаны в запросе INSERT
Пример обновления возраста пользователя с именем Igor в представлении:
Обратите внимание: обновление строки в представлении приводит к ее обновлению в базовой таблице.
В представление могут добавляться новые строки с помощью команды INSERT . При выполнении этой команды должны соблюдаться те же правила, что и при выполнении команды UPDATE .
С помощью команды DELETE можно удалять строки из представления.
Удаляем из представления пользователя, возраст которого составляет 26 лет:
Обратите внимание: удаление строки в представлении приводит к ее удалению в базовой таблице.
Удаление представления
Для удаления представления используется инструкция DROP VIEW :
Удаляем представление usersView :
HAVING
Предложение HAVING используется для фильтрации результатов группировки. WHERE используется для применения условий к колонкам, а HAVING — к группам, созданным с помощью GROUP BY .
HAVING должно указываться после GROUP BY , но перед ORDER BY (при наличии).
Транзакции
Транзакция — это единица работы или операции, выполняемой над БД. Это последовательность операций, выполняемых в логическом порядке. Эти операции могут запускаться как пользователем, так и какой-либо программой, функционирующей в БД.
Транзакция — это применение одного или более изменения к БД. Например, при создании/обновлении/удалении записи мы выполняем транзакцию. Важно контролировать выполнение таких операций в целях обеспечения согласованности данных и обработки возможных ошибок.
На практике, запросы, как правило, не отправляются в БД по одному, они группируются и выполняются как часть транзакции.
Свойства транзакции
Транзакции имеют 4 стандартных свойства (ACID):
- атомарность (atomicity) — все операции транзакции должны быть успешно завершены. В противном случае, транзакция прерывается, а все изменения отменяются (происходит откат к предыдущему состоянию)
- согласованность (consistency) — состояние должно изменться в полном соответствии с операциями транзакции
- изоляция или автономность (isolation) — транзакции не зависят друг от друга и не оказывают друг на друга никакого влияния
- долговечность (durability) — результат звершенной транзакции должен сохраняться при поломке системы
Управление транзакцией
Для управления транзакцией используются следующие команды:
- BEGIN|START TRANSACTION — запуск транзакции
- COMMIT — сохранение изменений
- ROLLBACK — отмена изменений
- SAVEPOINT — контрольная точка для отмены изменений
- SET TRANSACTION — установка характеристик текущей транзакции
Команды для управления транзакцией могут использоваться только совместно с такими запросами как INSERT , UPDATE и DELETE . Они не могут использоваться во время создания и удаления таблиц, поскольку эти операции автоматически отправляются в БД.
Удаляем пользователя, возраст которого составляет 26 лет, и отправляем изменения в БД:
Удаляем пользователя с именем Oleg и отменяем эту операцию:
Контрольные точки создаются с помощью такого синтаксиса:
Возврат к контрольной точке выполняется так:
Выполняем три запроса на удаление данных из users , создавая контрольные точки перед каждый удалением:
Отменяем два последних удаления, возвращаясь к контрльной точке sp2 , созданной после первого удаления:
Делаем выборку пользователей:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 31 | Moscow | active |
| 3 | Elena | 27 | Ekaterinburg | active |
| 4 | Oleg | 28 | Moscow | inactive |
Как видим, из таблицы был удален только пользователь с возрастом 26 лет.
Для удаление контрольной точки используется команда RELEASE SAVEPOINT . Естественно, после удаления контрольной точки, к ней нельзя будет вернуться с помощью ROLLBACK TO .
Команда SET TRANSACTION используется для инициализации транзакции, т.е. начала ее выполнения. При этом, можно определять некоторые характеристики транзакции. Например, так можно определить уровень доступа транзакции (доступна только для чтения или для записи тоже):
Временные таблицы
Некоторые СУБД поддерживают так называемые временные таблицы (temporary tables). Такие таблицы позволяют хранить и обрабатывать промежуточные результаты с помощью таких же запросов, как и при работе с обычными таблицами.
Временные таблицы могут быть очень полезными при необходимости хранения временных данных. Одной из главных особенностей таких таблиц является то, что они удаляются по завершении текущей сессии. При запуске скрипта временная таблица удаляется после завершения выполнения этого скрипта. При доступе к БД с помощью клиентской программы, такая таблица будет удалена после закрытия этой программы.
Временная таблица создается с помощью инструкции CREATE TEMPORARY TABLE , в остальном синтаксис создания таких таблиц идентичен синтаксису создания обычных таблиц.
Временная таблица удаляется точно также, как и обычная таблица, с помощью инструкции DROP TABLE .
Клонирование таблицы
Может возникнуть ситуация, когда потребуется получить точную копию существующей таблицы, а CREATE TABLE или SELECT окажется недостаточно в силу того, что мы хотим получить не только идентичную структуру, но также индексы, значения по умолчанию и т.д. копируемой таблицы.
В mysql , например, это можно сделать так:
- вызываем команду SHOW CREATE TABLE для получения инструкции, выполненной при создании таблицы, включая индексы и прочее
- меняем название таблицы и выполняем запрос. Получаем точную копию таблицы
- опционально: если требуется содержимое копируемой таблицы, можно также использовать инструкции INSERT INTO или SELECT
Подзапросы
Подзапрос — это внутренний (вложенный) запрос другого запроса, встроенный (вставленный) с помощью WHERE или других инструкций.
Подзапрос используется для получения данных, которые будут использованы основным запросом в качестве условия для фильтрации возвращаемых записей.
Подзапросы могут использоваться в инструкциях SELECT , INSERT , UPDATE и DELETE , а также с операторами = , < , > , >= , <= , IN , BETWEEN и т.д.
Правила использования подзапросов:
- они должны быть обернуты в круглые скобки
- подзапрос должен содержать только одну колонку для выборки, если основной запрос не содержит несколько таких колонок, которые сравниваются в подзапросе
- в подзапросе нельзя использовать команду ORDER BY , это можно сделать в основном запросе. В подзапросе для замены ORDER BY можно использовать GROUP BY
- подзапросы, возвращающие несколько значений, могут использоваться только с операторами, которые работают с наборами значений, такими как IN
- список SELECT не может содержать ссылки на значения, которые оцениваются (вычисляются) как BLOB , ARRAY , CLOB или NCLOB
- подзапрос не может быть сразу передан в функцию для установки значений
- команду BETWEEN нельзя использовать совместно с подзапросом. Тем не менее, в самомподзапросе указанную команду использовать можно
Подзапросы, обычно, используются в инструкции SELECT .
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 30 | Moscow | active |
| 3 | Elena | 27 | Ekaterinburg | active |
Подзапросы могут использоваться в инструкции INSERT . Эта инструкция добавляет в таблицу данные, возвращаемые подзапросом. При этом, данные, возвращаемые подзапросом, могут быть модифицированы любыми способами.
Подзапросы могут использоваться в инструкции UPDATE . При этом, данные из подзапроса могут использоваться для обновления любого количества колонок.
Данные, возвращаемые подзапросом, могут использоваться и для удаления записей.
Последовательности
Последовательность — это набор целых чисел (1, 2, 3 и т.д.), генерируемых автоматически. Последовательности часто используются в БД, поскольку многие приложения нуждаются в уникальных значениях, используемых для идентификации строк.
Приведенные ниже примеры рассчитаны на mysql .
Простейшим способом определения последовательности является использование AUTO_INCREMENT при создании таблицы:
Для того, чтобы заново пронумеровать строки с помощью автоматически генерируемых значений (например, при удалении большого количества строк), можно удалить колонку, содержащую такие значения и создать ее заново. Обратите внимание: такая таблица не должна быть частью объединения.
По умолчанию значения, генерируемые с помощью AUTO_INCREMENT , начинаются с 1. Для того, чтобы установить другое начальное значение достаточно указать, например, AUTO_INCREMENT = 100 — в этом случае нумерация строк начнется со 100.
Как расшифровывается язык запросов sql
SQL — язык структурированных запросов (SQL, Structured Query Language), который используется в качестве эффективного способа сохранения данных, поиска их частей, обновления, извлечения и удаления из базы данных.
Обращение к реляционным СУБД осуществляется именно благодаря SQL. С помощью него выполняются все основные махинации с базами данных, например:
- Извлекать данные из базы данных
- Вставлять записи в базу данных
- Обновлять записи в базе данных
- Удалять записи из базы данных
- Создавать новые базы данных
- Создавать новые таблицы в базе данных
- Создавать хранимые процедуры в базе данных
- Создавать представления в базе данных
- Устанавливать разрешения для таблиц, процедур и представлений
Язык SQL – универсальный язык для всех реляционных систем управления базами данных, но многие СУБД вносят свои изменения в язык, применяемый в них, тем самым отступая от стандарта. Такие языки называют диалектами или расширениями языка.
Вот некоторые из них:
- T-SQL – диалект Microsoft SQL Server
- PL/SQL – диалект Oracle Database
- PL/pgSQL – диалект PostgreSQL
Если вы знаете, что вам нужно изучать SQL, вам следует изучить стандартный SQL. Однако, если вы уже знаете, с какой конкретной базой данных вы будете работать, вероятно, лучше всего изучить её диалект SQL и просто знать, что разные базы данных могут использовать немного отличающийся синтаксис.
В нашем курсе мы будем использовать СУБД MySQL, ибо она достаточно популярная и в тоже время в ней используется близкий к стандартному SQL, хотя и с небольшими отличиями. Подробнее об отличиях.