Представления (VIEW) в MySQL
В комментариях Хабра упоминались вопросы по использованию представлений. Данный топик является обзором представлений, появившихся в MySQL версии 5.0. В нем рассмотрены вопросы создания, преимущества и ограничения представлений.
Что такое представление?
Представление (VIEW) — объект базы данных, являющийся результатом выполнения запроса к базе данных, определенного с помощью оператора SELECT, в момент обращения к представлению.
Представления иногда называют «виртуальными таблицами». Такое название связано с тем, что представление доступно для пользователя как таблица, но само оно не содержит данных, а извлекает их из таблиц в момент обращения к нему. Если данные изменены в базовой таблице, то пользователь получит актуальные данные при обращении к представлению, использующему данную таблицу; кэширования результатов выборки из таблицы при работе представлений не производится. При этом, механизм кэширования запросов (query cache) работает на уровне запросов пользователя безотносительно к тому, обращается ли пользователь к таблицам или представлениям.
Представления могут основываться как на таблицах, так и на других представлениях, т.е. могут быть вложенными (до 32 уровней вложенности).
Преимущества использования представлений:
- Дает возможность гибкой настройки прав доступа к данным за счет того, что права даются не на таблицу, а на представление. Это очень удобно в случае если пользователю нужно дать права на отдельные строки таблицы или возможность получения не самих данных, а результата каких-то действий над ними.
- Позволяет разделить логику хранения данных и программного обеспечения. Можно менять структуру данных, не затрагивая программный код, нужно лишь создать представления, аналогичные таблицам, к которым раньше обращались приложения. Это очень удобно когда нет возможности изменить программный код или к одной базе данных обращаются несколько приложений с различными требованиями к структуре данных.
- Удобство в использовании за счет автоматического выполнения таких действий как доступ к определенной части строк и/или столбцов, получение данных из нескольких таблиц и их преобразование с помощью различных функций.
Ограничения представлений в MySQL
- нельзя повесить триггер на представление,
- нельзя сделать представление на основе временных таблиц; нельзя сделать временное представление;
- в определении представления нельзя использовать подзапрос в части FROM,
- в определении представления нельзя использовать системные и пользовательские переменные; внутри хранимых процедур нельзя в определении представления использовать локальные переменные или параметры процедуры,
- в определении представления нельзя использовать параметры подготовленных выражений (PREPARE),
- таблицы и представления, присутствующие в определении представления должны существовать.
- только представления, удовлетворяющие ряду требований, допускают запросы типа UPDATE, DELETE и INSERT.
Создание представлений
view_name — имя создаваемого представления. select_statement — оператор SELECT, выбирающий данные из таблиц и/или других представлений, которые будут содержаться в представлении
- OR REPLACE — при использовании данной конструкции в случае существования представления с таким именем старое будет удалено, а новое создано. В противном случае возникнет ошибка, информирующая о сществовании представления с таким именем и новое представление создано не будет. Следует отметить одну особенность — имена таблиц и представлений в рамках одной базы данных должны быть уникальны, т.е. нельзя создать представление с именем уже существующей таблицы. Однако конструкция OR REPLACE действует только на представления и замещать таблицу не будет.
- ALGORITM — определяет алгоритм, используемый при обращении к представлению (подробнее речь об этом пойдет ниже).
- column_list — задает имена полей представления.
- WITH CHECK OPTION — при использовании данной конструкции все добавляемые или изменяемые строки будут проверяться на соответствие определению представления. В случае несоответствия данное изменение не будет выполнено. Обратите внимание, что при указании данной конструкции для необновляемого представления возникнет ошибка и представление не будет создано. (подробнее речь об этом пойдет ниже).
CREATE VIEW v AS SELECT a.id, b.id FROM a,b;
* This source code was highlighted with Source Code Highlighter .
CREATE VIEW v (a_id, b_id) AS SELECT a.id, b.id FROM a,b;
* This source code was highlighted with Source Code Highlighter .
CREATE VIEW v AS SELECT a.id a_id, b.id b_id FROM a,b;
* This source code was highlighted with Source Code Highlighter .
CREATE VIEW v AS SELECT group_concat( DISTINCT column_name oreder BY column_name separator ‘+’ ) FROM table_name;
* This source code was highlighted with Source Code Highlighter .
- Если в обоих операторах встречается условие WHERE, то оба этих условия будут выполнены как если бы они были объединены оператором AND.
- Если в определении представления есть конструкция ORDER BY, то она будет работать только в случае отсутствия во внешнем операторе SELECT, обращающемся к представлению, собственного условия сортировки. При наличии конструкции ORDER BY во внешнем операторе сортировка, имеющаяся в определении представления, будет проигнорирована.
- При наличии в обоих операторах модификаторов, влияющих на механизм блокировки, таких как HIGH_PRIORITY, результат их совместного действия неопределен. Для избежания неопределенности рекомендуется в определении представления не использовать подобные модификаторы.
Алгоритмы представлений
Существует два алгоритма, используемых MySQL при обращении к представлению: MERGE и TEMPTABLE.
В случае алгоритма MERGE, MySQL при обращении к представлению добавляет в использующийся оператор соответствующие части из определения представления и выполняет получившийся оператор.
В случае алгоритма TEMPTABLE, MySQL заносит содержимое представления во временную таблицу, над которой затем выполняется оператор обращенный к представлению.
Обратите внимание: в случае использования этого алгоритма представление не может быть обновляемым (см. далее).
При создании представления есть возможность явно указать используемый алгоритм с помощью необязательной конструкции [ALGORITHM =
UNDEFINED означает, что MySQL сам выбирает какой алгоритм использовать при обращении к представлению. Это значение по умолчанию, если данная конструкция отсутствует.
Использование алгоритма MERGE требует соответствия 1 к 1 между строками таблицы и основанного на ней представления.
Пусть наше представление выбирает отношение числа просмотров к числу ответов для тем форума:
CREATE VIEW v AS SELECT subject, num_views/num_replies AS param FROM topics WHERE num_replies>0;
* This source code was highlighted with Source Code Highlighter .
SELECT subject, param FROM v WHERE param>1000;
* This source code was highlighted with Source Code Highlighter .
SELECT subject, num_views/num_replies AS param FROM topics WHERE num_replies>0 AND num_views/num_replies>1000;
* This source code was highlighted with Source Code Highlighter .
Если в определении представления используются групповые функции (count, max, avg, group_concat и т.д.), подзапросы в части перечисления полей или конструкции DISTINCT, GROUP BY, то не выполняется требуемое алгоритмом MERGE соответствие 1 к 1 между строками таблицы и основанного на ней представления.
Пусть наше представление выбирает количество тем для каждого форума:
CREATE VIEW v AS SELECT forum_id, count (*) AS num FROM topics GROUP BY forum_id;
* This source code was highlighted with Source Code Highlighter .
* This source code was highlighted with Source Code Highlighter .
SELECT MAX ( count (*)) FROM topics GROUP BY forum_id;
* This source code was highlighted with Source Code Highlighter .
Выполнение этого запроса приводит к ошибке «ERROR 1111 (HY000): Invalid USE of GROUP function», так как используется вложенность групповых функций.
В этом случае MySQL использует алгоритм TEMPTABLE, т.е. заносит содержимое представления во временную таблицу (данный процесс иногда называют «материализацией представления»), а затем вычисляет MAX() используя данные временной таблицы:
CREATE TEMPORARY TABLE tmp_table SELECT forum_id, count (*) AS num FROM topics GROUP BY forum_id;
SELECT MAX (num) FROM tmp_table;
DROP TABLE tpm_table;
* This source code was highlighted with Source Code Highlighter .
- В случае UNDEFINED MySQL пытается использовать MERGE везде где это возможно, так как он более эффективен чем TEMPTABLE и, в отличие от него, не делает представление не обновляемым.
- Если вы явно указываете MERGE, а определение представления содержит конструкции запрещающие его использование, то MySQL выдаст предупреждение и установит значение UNDEFIND.
Обновляемость представлений
- Соответствие 1 к 1 между строками представления и таблиц, на которых основано представление, т.е. каждой строке представления должно соответствовать по одной строке в таблицах-источниках.
- Поля представления должны быть простым перечислением полей таблиц, а не выражениеями col1/col2 или col1+2.
Обновляемое представление может допускать добавление данных (INSERT), если все поля таблицы-источника, не присутствующие в представлении, имеют значения по умолчанию.
Обратите внимание: для представлений, основанных на нескольких таблицах, операция добавления данных (INSERT) работает только в случае если происходит добавление в единственную реальную таблицу. Удаление данных (DELETE) для таких представлений не поддерживается.
- Изменение данных (UPDATE) будет происходить только если строка с новыми значениями удовлетворяет условию WHERE в определении представления.
- Добавление данных (INSERT) будет происходить только если новая строка удовлетворяет условию WHERE в определении представления.
- Для LOCAL происходит проверка условия WHERE только в собственном определении представления.
- Для CASCADED происходит проверка для всех представлений на которых основанно данное представление. Значением по умолчанию является CASCADED.
punbb > CREATE OR REPLACE VIEW v AS
-> SELECT forum_name, `subject`, num_views FROM topics,forums f
-> WHERE forum_id=f.id AND num_views>2000 WITH CHECK OPTION ;
Query OK, 0 rows affected (0.03 sec)
punbb > UPDATE v SET num_views=2003 WHERE subject= ‘test’ ;
Query OK, 0 rows affected (0.03 sec)
Rows matched: 1 Changed: 0 WARNINGS: 0
punbb > SELECT subject, num_views FROM topics WHERE subject= ‘test’ ;
+———+————+
| subject | num_views |
+———+————+
| test | 2003 |
+———+————+
1 rows IN SET (0.01 sec)
* This source code was highlighted with Source Code Highlighter .
Однако, если мы попробуем установить значение num_views меньше 2000, то новое значение не будет удовлетворять условию WHERE num_views>2000 в определении представления и обновления не произойдет.
punbb > UPDATE v SET num_views=1999 WHERE subject= ‘test’ ;
ERROR 1369 (HY000): CHECK OPTION failed ‘punbb.v’
* This source code was highlighted with Source Code Highlighter .
Не все обновляемые представления позволяют добавление данных:
punbb > INSERT INTO v (subject,num_views) VALUES ( ‘test1’ ,4000);
ERROR 1369 (HY000): CHECK OPTION failed ‘punbb.v’
* This source code was highlighted with Source Code Highlighter .
Причина в том, что значением по умолчанию колонки forum_id является 0, поэтому добавляемая строка не удовлетворяет условию WHERE forum_id=f.id в определении представления. Указать же явно значение forum_id мы не можем, так как такого поля нет в определении представления:
punbb > INSERT INTO v (forum_id,subject,num_views) VALUES (1, ‘test1’ ,4000);
ERROR 1054 (42S22): Unknown COLUMN ‘forum_id’ IN ‘field list’
* This source code was highlighted with Source Code Highlighter .
punbb > INSERT INTO v (forum_name) VALUES ( ‘TEST’ );
Query OK, 1 row affected (0.00 sec)
* This source code was highlighted with Source Code Highlighter .
Таким образом, наше представление, основанное на двух таблицах, позволяет обновлять обе таблицы и добавлять данные только в одну из них.
Представление (VIEW) в T-SQL – описание и примеры использования
Приветствую всех посетителей сайта Info-Comp.ru! Сегодня мы с Вами поговорим о таких объектах Microsoft SQL Server, как «Представления», Вы узнаете, что это за объекты, для чего они нужны, а также как создавать, изменять и удалять представления на языке T-SQL.

Представление (VIEW) в Microsoft SQL Server
Представление (VIEW) – это объект базы данных Microsoft SQL Server, который хранит в себе запрос SELECT и в случае обращения к данному объекту будет возвращен результирующий набор данных, который формирует запрос, указанный в определении представления.
Иными словами, это виртуальная (логическая) таблица, она не содержит в себе данных, но к ней можно обращаться как к обычной таблице, и она будет возвращать Вам данные. Обычно такой объект называют «Вьюха».
Для чего нужны представления
Если достаточно часто в своих SQL запросах Вы используете однотипные вложенные запросы, которые возвращают табличные данные, т.е. являются производными таблицами, то для удобства и сокращения кода Вы можете сохранить такие вложенные запросы в виде представления. И затем, где Вам требуется использовать именно тот набор данных, который Вы указали в запросе, Вы будете указывать название представления, точно так же как мы указываем название таблиц, согласитесь — это очень удобно!
Таким образом, представления нужны для:
- Упрощения и сокращения кода запроса;
- Повышения читабельности кода запроса;
- Сокрытия сложности реализации задачи от пользователя;
- Обеспечения эффективных путей доступа к данным;
- Обеспечения корректности производных данных;
- Более легкого управления. Чтобы внести изменения в алгоритм, формирующий данные, которые возвращает представление, не требуется изменять код везде, где используется этот алгоритм, достаточно изменить код в одном определении представления.
Как Вы понимаете, представления мы можем использовать не только для упрощения и сокращения кода SQL запроса, а еще для повышения безопасности, сокрытия сложности реализации алгоритмов и для обеспечения корректности производных данных.
Какие бывают представления
- Пользовательские – это те, которые мы сами создаем;
- Системные – это представления, которые уже есть в SQL сервере. Они возвращают нам системную информацию.
Работа с представлениями на T-SQL
Исходные данные
Сначала нам необходимо создать тестовые данные для наших примеров.
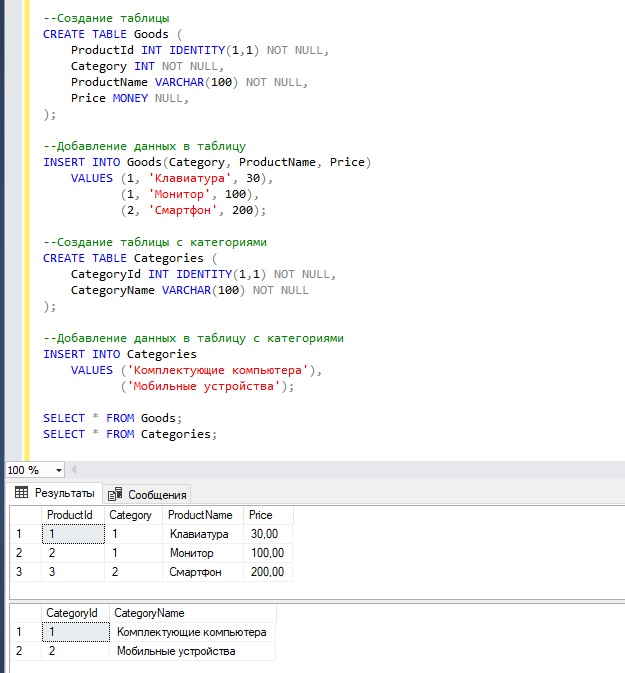
Допустим, у нас будет таблица Goods, которая хранит некую информацию о товарах, и таблица Categories, которая хранит данные о категориях товара.
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней очень подробно рассмотрены основные конструкции языка.
Создание представлений
Представим, что нам постоянно требуется знать, сколько товаров в той или иной категории, но писать каждый раз SQL запрос на получение таких данных нам не хочется и это не очень удобно. Поэтому мы приняли решения сохранить запрос на получение таких данных в виде представления и, когда нам потребуется узнать количество товаров в категории, мы просто будем обращаться к этому представлению.
Создается представление с помощью инструкции CREATE VIEW.
Для решения нашей задачи мы можем создать следующее представление.
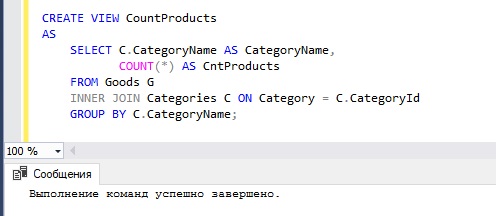
После инструкции CREATE VIEW мы указали название представления, затем мы указали ключевое слово AS и только после этого мы написали запрос, результирующий набор которого и будет содержать наше представление.
Примечание! В представлении нельзя использовать секцию ORDER BY, т.е. сортировку, в случае необходимости, отсортировать данные Вы можете, когда будете обращаться к этому представлению. Использование ORDER BY возможно, только если указан оператор TOP.
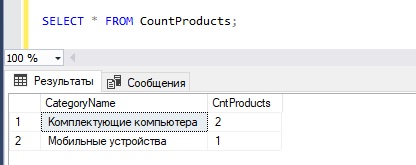
Теперь, для того чтобы получить данные о количестве товаров в категории, мы можем обратиться к этому представлению, например, как к обычной таблице.
Изменение представлений
А сейчас давайте допустим, что нам нужно, чтобы это представление возвращало еще и идентификатор категории, если Вы обратили внимание, то в предыдущем примере таких данных нет. Для этого используем инструкцию ALTER VIEW, которая подразумевает изменение представления.
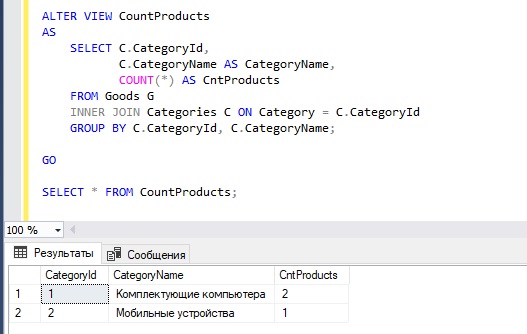
В данном случае мы написали инструкцию ALTER VIEW, которая говорит SQL серверу, что мы хотим изменить существующий объект, затем указали название представления, чтобы сервер мог определить, какое именно представление мы хотим изменить, после ключевого слова AS мы указали новое определение представления, т.е. измененный запрос SELECT.
Чтобы отделить инструкцию изменения представления от SQL запроса на выборку, мы написали команду GO.
Удаление представлений
Если Вам представление больше не требуется, т.е. Вы им больше не будете пользоваться, и оно не используется в других представлениях, функциях или процедурах, иными словами, на него никто не ссылается, то Вы его можете удалить, это делается с помощью инструкции DROP VIEW.
Теперь данного представления больше нет, и к нему Вы больше обратиться не сможете.
Обновляемые представления в Microsoft SQL Server
Кроме того, что к представлению можно обращаться и извлекать данные, представление позволяет еще и изменять данные базовой таблицы, такие представления называются «Обновляемые представления». Однако для этого необходимо выполнение следующих условий:
- Любое изменение (UPDATE, INSERT или DELETE) должно касаться столбцов только одной базовой таблицы;
- Столбцы, данные которых Вы хотите изменить, должны напрямую ссылаться на столбцы базовой таблицы, иными словами, нельзя внести изменения в столбцы, которые были сформированы в представлении, например, агрегатной функцией или другими вычислениями.
Допустим, у нас есть представление, которое возвращает список товаров. Для примера мы его назвали GoodsUpdate.
И в данном случае мы можем изменить данные, хранящиеся в таблице Goods, через представление, не обращаясь к этой таблице напрямую.
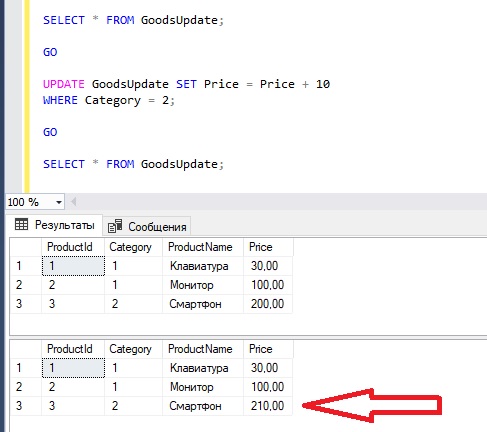
Мы видим, что данные успешно изменены.
Заметка! Для комплексного изучения языка SQL и T-SQL рекомендую пройти онлайн-курсы по T-SQL, на которых используется последовательная методика обучения и рассматриваются все объекты SQL Server и конструкции языка T-SQL.
На сегодня это все, надеюсь, материал был Вам интересен и полезен, до новых встреч!
Getting started with SQL Views
![]()
A SQL view returns a table containing only the information you want the end user to see.
Databases are designed to store millions of rows of data, and it can be difficult to query or filter a vast amount of data repeatedly using the same query or filter commands. With SQL views, it becomes much easier.
The type of table a view creates is called a virtual table. A virtual table doesn’t store data, rather it rebuilds itself every time the table is queried.
End users aren’t querying directly the original table created in the database using create table command, but rather a copy of the original table.
This copy of the original table can have more columns returned from it or it can have fewer columns returned. More columns when two or more tables are joined together, and fewer columns when only specific columns are selected.
For example, suppose you are a data analyst working in a bank. The bank manager has authorized you to run an analysis of employee data.
Part of the analysis requires that you use the employee’s table. This employee’s table contains fields/column names such as first and last name, age, contact details, email address, and NIN (National Identification Number).
You do not want to show the employee’s contact details, email address, and NIN. In this scenario, a view can be created that returns the employee’s general information (first name, last name, age), while sensitive information such as the NIN, email address, and contact details, if not needed for the analysis can be hidden.
Another example requires you to combine data from two or more tables. Instead of running the same join query command repeatedly when you want to have access to data, you can create a view that hides all the complex SQL join queries. With this, you can query your underlying data with a simple select statement without having to type repeatedly the complex SQL queries for joining tables.
Benefits of using views
Simplify Complex Queries:
Views can be used to simplify complex queries by breaking them down into smaller, more manageable pieces.
Limited Access:
Views can be used to enforce security by limiting access to sensitive data. For example, you can create a view that only shows the first name and last name of employees, but not their salary or other confidential information.
Consistency:
Views can be used to enforce consistency ensuring that all queries use a common data definition.
Creating SQL views.
For this, we will be using the PostgreSQL database.
To create a view, you use the CREATE VIEW statement
CREATE VIEW: Begin the creation of the views
view_name: The name of the view to be created
AS: Specifies the table(s) from which we are populating data from
Setting up a Database using PostgreSQL
For this tutorial, we will be creating our database. Doing so I believe will cement the knowledge and help you comprehend the concept better.
Create Database
With our database created, let’s now create tables and populate rows into it.
Insert records
Creating the view
To create this view, we would want to exclude the employees’ salary and employee_id from the result of the SQL query. This information is considered sensitive and only important to internal management. External management or auditors aren’t expected to see it.
I usually prefix the name of the view with a V, to signify that the table created is a views table
Query a view
Once a view is created, it can be queried like a regular table.
When creating the view with the create view statement, we selected specific columns from the Vemployee_data table, which excluded the salary column. Here the salary column is no longer returned from the result of the query.
Views with conditions
Using the where clause, we filter the views table for employees who are female.
We can also define the filter condition when creating the view.
Now when you query the newly created view, it returns all rows where the employee’s gender is male.
I usually filter my data after the underlying views have been created, and I would encourage you to do the same. Unless your analysis requires a particular use case where not all rows from the original table should be returned. E.g: You are trying to run your analysis only for male employees, so returning all rows for both genders would be a waste of time and computing resources.
Insert data into a view
In general, it isn’t recommended to directly insert data into a views table as views are virtual tables and don’t store data on their own. However, there are advanced cases where you can perform data insertion through the view. This is beyond the scope of this article.
It is recommended, to insert the data directly through the original table.
Insert data through the original table
If you add data to one of the tables from which the view is derived, the data will automatically be added and updated in the view.
Execute the view
Updating a View
In most cases, you can’t update a view directly. However, you can update the original table and the changes will be reflected in the view.
Modify a View
In PostgreSQL, you can modify a view by using the ALTER VIEW statement. This statement allows you to change the definition of the view without affecting the underlying data in the tables. To alter a view, you can use the following syntax:
To replace a particular column from the view, you first have to drop the existing view and then recreate it.
Here, the create view query is named Vemployee_info because it was renamed above with the ALTER VIEW command.
Here the Vemployee_info view is modified to exclude the last_name column.
Deleting/Removing Views
To delete/remove a view, use the DROP VIEW command .
DROP VIEW view_name
Where view_name is the name of the views you want to delete
Summary
SQL views are a powerful tool that allows you to simplify complex queries, enforce security, and simplify the structure of tables.
In this tutorial, you’ve learned
What SQL views are,
Why views can be useful.
How to create, query, change, and delete them from a database.
Always remember, functionalities and syntax supported on views vary between relational database management systems (RDBMS).
Система управления базами данных SQLite. Изучаем язык запросов SQL и реляционные базы данных на примере библиотекой SQLite3. Курс для начинающих.
Тема 14: VIEW в SQL на примере базы данных SQLite: CREATE, DROP, UPDATE
- 17.07.2016
- SQLite библиотека, Базы данных
- Комментариев нет
Привет, посетитель сайта ZametkiNaPolyah.ru! Продолжаем изучать базы данных и наше знакомство с библиотекой SQLite3. В этой записи мы с вами разберемся с представлениями и их использованием в реляционных базах данных. Вообще VIEW в SQL довольно полезная штука, которая позволяет упростить SQL запросы SELECT, а также скрыть логику базы данных от пользователей и программного кода, тем самым создав дополнительный уровень абстракции, который защищает наши базы данных от вредоносного вмешательства. Многие считают VIEW виртуальными таблицами, что не совсем правильно, так как представление — это запрос хранимый в базе данных и доступный по его имени (VIEW это такой же объект базы данных, как скажем, триггер или таблица). Делать выборку данных из VIEW во многих СУБД намного быстрее, например, MySQL сервер любит кэшировать результаты запросов, а VIEW, как вы поняли, есть ни что иное, как запрос.

VIEW в SQL на примере базы данных SQLite: CREATE, DROP, UPDATE.
В этой записи мы с вами будем разбираться с использованием VIEW в SQL и реляционных базах данных на пример библиотеки SQLite. Сначала мы поговорим о том, что собой представляют VIEW в базах данных и разберемся с тем, как мы можем использовать представления. Затем поговорим про особенности работы представлений в SQLite3 и разберем SQL синтаксис VIEW, реализованный в данной СУБД. И затем попробуем поработать с VIEW в базах данных под управлением SQLite.
Что такое VIEW в контексте языка SQL и баз данных?
Прежде чем ответить на вопрос зачем нужны VIEW в SQL и реляционных базах данных давайте ответим на вопрос: «что такое VIEW в языке запросов SQL?». В Википедии, на мой взгляд, формулировка определения VIEW в SQL написана неправильно. Так как представление не является виртуальной таблицей (как минимум, для создания виртуальных таблиц в SQLite предусмотрен отдельный синтаксис).
Документация MySQL говорит нам о том, что представление можно рассматривать, как виртуальную таблицу, но не утверждает, что VIEW – это VIRTUAL TABLE. В разделе VIEW документации Oracle упоминаний про виртуальную таблицу при беглом чтении я не встретил. Конечно, кто-то со мной может не согласиться, но я считаю, что VIEW – это не виртуальная таблица. Итак, мы разобрались с тем, чем не является VIEW в SQL и реляционных базах данных.
Теперь давайте дадим правильное определение термину VIEW в контексте языка SQL. VIEW – это хранимый запрос в базе данных. Возможно, представление называют виртуальной таблицей (virtual table) по той причине, что структура VIEW полностью повторяет структуру результирующей таблицы запроса SELECT, но опять же, это не повод называть VIEW виртуальной таблицей.
Сервер MySQL довольно быстро работает с представлениями за счет того, что MySQL очень любит кэшировать результаты запросов, в принципе, многие современные системы управления базами данных любят и хорошо кэшируют запросы, поэтому вы не всегда сможете заметить разницу работы между VIEW и таблицей базы данных, особенно, если ваши таблицы небольшие.
Вместо термина VIEW в различных источниках вы можете встретит термины представления или просмотры. Мне удобнее использовать термин представление. Давайте вернемся к определению термина представления в базах данных. Итак, представление – это хранимый в базе данных запрос, которому нужно дать имя. Когда мы создали представление, мы можем обращаться к нему, как к обычной таблице базы данных, используя то имя, которое мы написали после команды CREATE VIEW.
Единственная команда языка SQL, возвращающая в результате своей работы таблицу – это команда SELECT, с помощь которой мы не только делаем выборку данных, но и создаем VIEW в базе данных. Практически в любой СУБД для работы с представлениями доступны все команды манипуляции данными, но в библиотеки SQLite3 это утверждение не верно, об этом мы поговорим чуть ниже.
Напомним себе, что команды: UPDATE, SELECT, INSERT, DELETE, относятся к командам манипуляции данными. VIEW создается на основе запроса SELECT. Но, например, в базах данных MySQL, вы не сможете использовать команды UPDATE, INSERT, DELETE, если SQL запрос создающий VIEW содержит:
- Функции агрегации.
- Ключевое слово LIMIT.
- Клаузулу GROUP BY, позволяющую сделать группировку данных.
- Клаузула HAVING, фильтрующая данные после группировки.
- Операторы UNION и UNION ALL, объединяющие результаты двух запросов.
- Любой подзапрос SELECT, даже подзапрос JOIN, объединяющий две таблицы.
- Если запрос содержит пользовательские переменные.
- Если нет базовой таблицы.
Поэтому рекомендую вам сперва ознакомиться с документацией той или иной СУБД, прежде чем начать создавать представления в базе данных. Например, документация MySQL так и говорит, что команды манипуляции данными (за исключением SELECT, который можно применять к любому представлению) можно применять к VIEW в том случае, когда строки VIEW совпадают со строками таблицы в базе данных (это несколько вольный и не совсем точный перевод).
Мы разобрались с тем, что VIEW – это именованный запрос SELECT, который хранится в базе данных. Каждый раз, когда мы обращаемся к VIEW, СУБД выполняет этот запрос SELECT, а следом за ним, она выполняет наш запрос. Думаю, ничего сложно в понимание того, что такое VIEW нет, давайте теперь разберемся для чего мы можем использовать VIEW.
Использование представлений в SQL и реляционных базах данных
Первое и очевидное применение VIEW в базах данных заключается в том, чтобы упростить запросы на выборку данных. Ведь нам же не хочется писать полотно SELECT, которое объединяет три-четыре таблицы каждый раз, а потом еще задавать какие-нибудь условия выборки данных клаузулой WHERE? Итак, первое, для чего мы можем использовать представление – это для упрощения запросов выборки данных.
Второй пункт можно назвать безопасность. Во-первых, при помощи VIEW можно скрыть бизнес-логику и архитектуру базы данных от прикладных приложений, сделав так, что программа будет обращаться не к таблицам базы данных, а к представлениям. Во-вторых, так вы избавитесь от некоторых видов SQL-инъекций, плюсом к этому, особо талантливые программисты лишаться «чудесной возможности» конкатенировать SQL запросы (как только вы увидите, что программист конкатенирует SQL запрос, можете зарядить ему в щи с вертушки и прокричать: я угорел по базам данных, а ты не знаешь даже таких простых вещей), тем самым вы еще уменьшите вариативность атак на вашу базу данных.
Третий вариант применения VIEW сводится к обновлениям. Вы редко можете встретить базу данных без прикладного приложения. Мир не стоит на месте, всё летит, всё развивается, компании растут и объединяются, у клиентов появляются всё новые потребности и рано или поздно старые приложения становятся неудобными и возникает потребность в их модификации. Мы уже говорили, что VIEW позволяют скрывать бизнес-логику базы данных, но не всегда, создавая базу данных, вы создаете представления. Поэтому если у вас возникла потребность в обновлении программного кода, работающего с базой данных, вы можете создать новую структуру базы данных в виде представлений, с которой будет работать новый программный код, тем самым вы разделите схему хранения данных и схему представления данных. Если потребности в разделении схем нет, то в дальнейшем вы можете отказаться от использования VIEW и вернуться к таблицам, после того, как код приложения будет обновлен.
Пожалуй, это три самых важных аспекта работы с базами данных, для которых можно и даже нужно использовать представления.
Особенности работы с VIEW в базах данных SQLite
Теперь поговорим про особенности VIEW в базах данных SQLite, мы уже говорили о том, что представления в SQLite нельзя редактировать, их можно только создавать, удалять и делать выборку из VIEW, в то время, как другие СУБД позволяют выполнять другие команды манипуляции данными представлений.
Но это не совсем так, все дело в том, что SQLite не дает возможность редактировать представления при помощи обычных SQL запросов. Но в базах данных есть триггеры, которые успешно эмитируют работу команд UPDATE, INSERT и DELETE. Соответственно, если мы можем:
То ничто нам не помешает выполнить те же самые операции с VIEW в SQLite, правда они будут немного сложнее из-за того, что нам придется использовать триггеры.
SQL синтаксис VIEW в базах данных SQLite
Давайте разберемся с синтаксисом SQL, реализованным в SQLite, который позволяет нам создавать и удалять представления из базы данных. Начнем мы с синтаксиса создания представлений в SQLite, он показан на рисунке ниже.
SQL синтаксис создания VIEW в базах данных SQLite
Отметим, что создание VIEW начинается с той же команды, что и создание таблицы в базе данных: с команды CREATE. Это обусловлено тем, что VIEW – это такой же объект базы данных, как и таблица. Далее мы указываем, что хотим создать представление при помощи ключевого слова VIEW. Представление может быть временным, поэтому после ключевого слова CREATE вы можете использовать слово TEMP или TEMPORARY. Если вы не уверены, что создаете представление с уникальным именем и не хотите возникновения ошибок при создании VIEW в базе данных, то можете использовать ключевую фразу IF NOT EXIST (кстати, оператор EXISTS может быть использован для создания подзапроса SELECT). Далее вам необходимо указать имя представления, которое должно быть уникальным, в качестве имени можно использовать квалификатор, в том случае, если вы работаете с несколькими базами данных и хотите быть уверенным в том, что создаете VIEW для нужной базы данных.
После имени представления идет ключевое слово AS и запрос SELECT, который как раз-таки и будет храниться в файле базы данных SQLite и к которому SQLite будет обращаться по тому имени, которое вы указали при создании VIEW.
Теперь рассмотрим SQL синтаксис удаления VIEW из базы данных под управлением SQLite3. Он показан на рисунке ниже.
SQL синтаксис удаления VIEW из базы данных под управлением SQLite3
Хоть обычное представление, хоть временное, удаляются из базы данных под управлением SQLite одинаково: ключевое слово DROP, за которым следует VIEW, говорит SQLite о том, что вы хотите удалить из базы данных не просто объект, а представление. Далее следует конструкция IF EXISTS, которая осуществляет проверку наличия представления в базе данных, чтобы SQLite не возвращала ошибки в том случае, если представление, которое вы хотите удалить, уже удалено. После чего идет имя представления или квалификатор.
Отметим, что для представлений в SQLite команда ALTER не реализована. Если вам нужно изменить структуру VIEW, то вам нужно удалить старое представление, а затем создать новой и с новой структурой.
Итак, мы разобрались с SQL синтаксисом VIEW в базах данных SQLite и можем начинать работать с представлениями.