How to Create and Manipulate SQL Databases with Python

Craig Dickson

Python and SQL are two of the most important languages for Data Analysts.
In this article I will walk you through everything you need to know to connect Python and SQL.
You’ll learn how to pull data from relational databases straight into your machine learning pipelines, store data from your Python application in a database of your own, or whatever other use case you might come up with.
Together we will cover:
- Why learn how to use Python and SQL together?
- How to set up your Python environment and MySQL Server
- Connecting to MySQL Server in Python
- Creating a new Database
- Creating Tables and Table Relationships
- Populating Tables with Data
- Reading Data
- Updating Records
- Deleting Records
- Creating Records from Python Lists
- Creating re-usable functions to do all of this for us in the future
That is a lot of very useful and very cool stuff. Let’s get into it!
A quick note before we start: there is a Jupyter Notebook containing all the code used in this tutorial available in this GitHub repository. Coding along is highly recommended!
The database and SQL code used here is all from my previous Introduction to SQL series posted on Towards Data Science (contact me if you have any problems viewing the articles and I can send you a link to see them for free).
If you are not familiar with SQL and the concepts behind relational databases, I would point you towards that series (plus there is of course a huge amount of great stuff available here on freeCodeCamp!)
Why Python with SQL?
For Data Analysts and Data Scientists, Python has many advantages. A huge range of open-source libraries make it an incredibly useful tool for any Data Analyst.
We have pandas, NumPy and Vaex for data analysis, Matplotlib, seaborn and Bokeh for visualisation, and TensorFlow, scikit-learn and PyTorch for machine learning applications (plus many, many more).
With its (relatively) easy learning curve and versatility, it’s no wonder that Python is one of the fastest-growing programming languages out there.
So if we’re using Python for data analysis, it’s worth asking — where does all this data come from?
While there is a massive variety of sources for datasets, in many cases — particularly in enterprise businesses — data is going to be stored in a relational database. Relational databases are an extremely efficient, powerful and widely-used way to create, read, update and delete data of all kinds.
The most widely used relational database management systems (RDBMSs) — Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2 — all use the Structured Query Language (SQL) to access and make changes to the data.
Note that each RDBMS uses a slightly different flavour of SQL, so SQL code written for one will usually not work in another without (normally fairly minor) modifications. But the concepts, structures and operations are largely identical.
This means for a working Data Analyst, a strong understanding of SQL is hugely important. Knowing how to use Python and SQL together will give you even more of an advantage when it comes to working with your data.
The rest of this article will be devoted to showing you exactly how we can do that.
Getting Started
Requirements & Installation
To code along with this tutorial, you will need your own Python environment set up.
I use Anaconda, but there are lots of ways to do this. Just google «how to install Python» if you need further help. You can also use Binder to code along with the associated Jupyter Notebook.
We will be using MySQL Community Server as it is free and widely used in the industry. If you are using Windows, this guide will help you get set up. Here are guides for Mac and Linux users too (although it may vary by Linux distribution).
Once you have those set up, we will need to get them to communicate with each other.
For that, we need to install the MySQL Connector Python library. To do this, follow the instructions, or just use pip:
We are also going to be using pandas, so make sure that you have that installed as well.
Importing Libraries
As with every project in Python, the very first thing we want to do is import our libraries.
It is best practice to import all the libraries we are going to use at the beginning of the project, so people reading or reviewing our code know roughly what is coming up so there are no surprises.
For this tutorial, we are only going to use two libraries — MySQL Connector and pandas.
We import the Error function separately so that we have easy access to it for our functions.
Connecting to MySQL Server
By this point we should have MySQL Community Server set up on our system. Now we need to write some code in Python that lets us establish a connection to that server.
A function to connect to our MySQL Server
Creating a re-usable function for code like this is best practice, so that we can use this again and again with minimum effort. Once this is written once you can re-use it in all of your projects in the future too, so future-you will be grateful!
Let’s go through this line by line so we understand what’s happening here:
The first line is us naming the function (create_server_connection) and naming the arguments that that function will take (host_name, user_name and user_password).
The next line closes any existing connections so that the server doesn’t become confused with multiple open connections.
Next we use a Python try-except block to handle any potential errors. The first part tries to create a connection to the server using the mysql.connector.connect() method using the details specified by the user in the arguments. If this works, the function prints a happy little success message.
The except part of the block prints the error which MySQL Server returns, in the unfortunate circumstance that there is an error.
Finally, if the connection is successful, the function returns a connection object.
We use this in practice by assigning the output of the function to a variable, which then becomes our connection object. We can then apply other methods (such as cursor) to it and create other useful objects.
Here, pw is a variable containing the root password for our MySQL Server as a string.
This should produce a success message:

Hooray!
Creating a New Database
Now that we have established a connection, our next step is to create a new database on our server.
In this tutorial we will do this only once, but again we will write this as a re-usable function so we have a nice useful function we can re-use for future projects.
This function takes two arguments, connection (our connection object) and query (a SQL query which we will write in the next step). It executes the query in the server via the connection.
We use the cursor method on our connection object to create a cursor object (MySQL Connector uses an object-oriented programming paradigm, so there are lots of objects inheriting properties from parent objects).
This cursor object has methods such as execute, executemany (which we will use in this tutorial) along with several other useful methods.
If it helps, we can think of the cursor object as providing us access to the blinking cursor in a MySQL Server terminal window.
![]() You know, this one.
You know, this one.
Next we define a query to create the database and call the function:

All the SQL queries used in this tutorial are explained in my Introduction to SQL tutorial series, and the full code can be found in the associated Jupyter Notebook in this GitHub repository, so I will not be providing explanations of what the SQL code does in this tutorial.
This is perhaps the simplest SQL query possible, though. If you can read English you can probably work out what it does!
Running the create_database function with the arguments as above results in a database called ‘school’ being created in our server.
Why is our database called ‘school’? Perhaps now would be a good time to look in more detail at exactly what we are going to implement in this tutorial.
Our Database
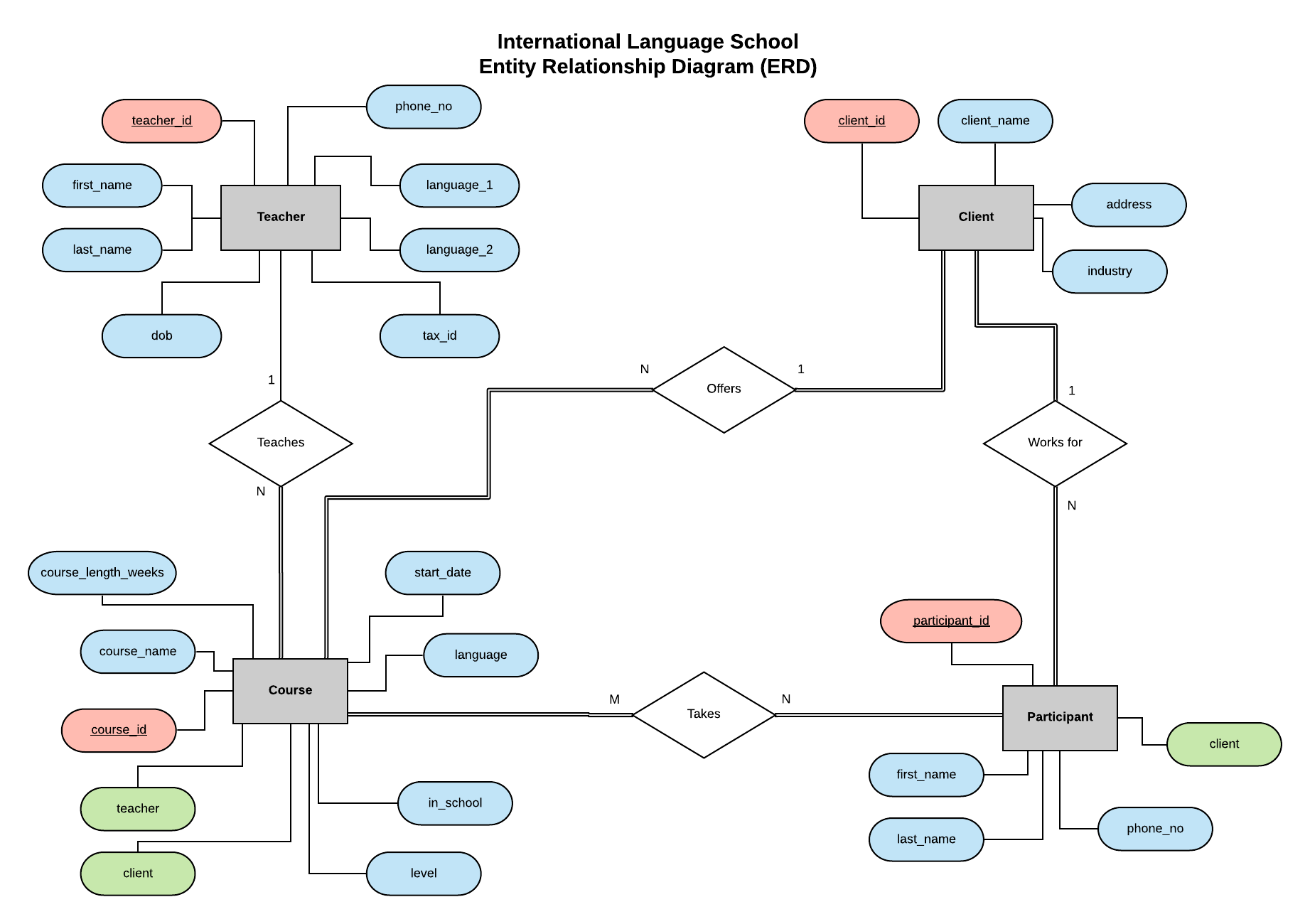
The Entity Relationship Diagram for our database.
Following the example in my previous series, we are going to be implementing the database for the International Language School — a fictional language training school which provides professional language lessons to corporate clients.
This Entity Relationship Diagram (ERD) lays out our entities (Teacher, Client, Course and Participant) and defines the relationships between them.
All the information regarding what an ERD is and what to consider when creating one and designing a database can be found in this article.
The raw SQL code, database requirements, and data to go into the database is all contained in this GitHub repository, but you’ll see it all as we go through this tutorial too.
Connecting to the Database
Now that we have created a database in MySQL Server, we can modify our create_server_connection function to connect directly to this database.
Note that it’s possible — common, in fact — to have multiple databases on one MySQL Server, so we want to always and automatically connect to the database we’re interested in.
We can do this like so:
This is the exact same function, but now we take one more argument — the database name — and pass that as an argument to the connect() method.
Creating a Query Execution Function
The final function we’re going to create (for now) is an extremely vital one — a query execution function. This is going to take our SQL queries, stored in Python as strings, and pass them to the cursor.execute() method to execute them on the server.
This function is exactly the same as our create_database function from earlier, except that it uses the connection.commit() method to make sure that the commands detailed in our SQL queries are implemented.
This is going to be our workhorse function, which we will use (alongside create_db_connection) to create tables, establish relationships between those tables, populate the tables with data, and update and delete records in our database.
If you’re a SQL expert, this function will let you execute any and all of the complex commands and queries you might have lying around, directly from a Python script. This can be a very powerful tool for managing your data.
Creating Tables
Now we’re all set to start running SQL commands into our Server and to start building our database. The first thing we want to do is to create the necessary tables.
Let’s start with our Teacher table:
First of all we assign our SQL command (explained in detail here) to a variable with an appropriate name.
In this case we use Python’s triple quote notation for multi-line strings to store our SQL query, then we feed it into our execute_query function to implement it.
Note that this multi-line formatting is purely for the benefit of humans reading our code. Neither SQL nor Python ‘care’ if the SQL command is spread out like this. So long as the syntax is correct, both languages will accept it.
For the benefit of humans who will read your code, however, (even if that will only be future-you!) it is very useful to do this to make the code more readable and understandable.
The same is true for the CAPITALISATION of operators in SQL. This is a widely-used convention that is strongly recommended, but the actual software that runs the code is case-insensitive and will treat ‘CREATE TABLE teacher’ and ‘create table teacher’ as identical commands.

Running this code gives us our success messages. We can also verify this in the MySQL Server Command Line Client:

Great! Now let’s create the remaining tables.
This creates the four tables necessary for our four entities.
Now we want to define the relationships between them and create one more table to handle the many-to-many relationship between the participant and course tables (see here for more details).
We do this in exactly the same way:
Now our tables are created, along with the appropriate constraints, primary key, and foreign key relations.
Populating the Tables
The next step is to add some records to the tables. Again we use execute_query to feed our existing SQL commands into the Server. Let’s again start with the Teacher table.
Does this work? We can check again in our MySQL Command Line Client:

Looks good!
Now to populate the remaining tables.
Amazing! Now we have created a database complete with relations, constraints and records in MySQL, using nothing but Python commands.
We have gone through this step by step to keep it understandable. But by this point you can see that this could all very easily be written into one Python script and executed in one command in the terminal. Powerful stuff.
Reading Data
Now we have a functional database to work with. As a Data Analyst, you are likely to come into contact with existing databases in the organisations where you work. It will be very useful to know how to pull data out of those databases so it can then be fed into your python data pipeline. This is what we are going to work on next.
For this, we will need one more function, this time using cursor.fetchall() instead of cursor.commit(). With this function, we are reading data from the database and will not be making any changes.
Again, we are going to implement this in a very similar way to execute_query. Let’s try it out with a simple query to see how it works.

Exactly what we are expecting. The function also works with more complex queries, such as this one involving a JOIN on the course and client tables.

For our data pipelines and workflows in Python, we might want to get these results in different formats to make them more useful or ready for us to manipulate.
Let’s go through a couple of examples to see how we can do that.
Formatting Output into a List

Formatting Output into a List of Lists

Formatting Output into a pandas DataFrame
For Data Analysts using Python, pandas is our beautiful and trusted old friend. It’s very simple to convert the output from our database into a DataFrame, and from there the possibilities are endless!

Hopefully you can see the possibilities unfolding in front of you here. With just a few lines of code, we can easily extract all the data we can handle from the relational databases where it lives, and pull it into our state-of-the-art data analytics pipelines. This is really helpful stuff.
Updating Records
When we are maintaining a database, we will sometimes need to make changes to existing records. In this section we are going to look at how to do that.
Let’s say the ILS is notified that one of its existing clients, the Big Business Federation, is moving offices to 23 Fingiertweg, 14534 Berlin. In this case, the database administrator (that’s us!) will need to make some changes.
Thankfully, we can do this with our execute_query function alongside the SQL UPDATE statement.
Note that the WHERE clause is very important here. If we run this query without the WHERE clause, then all addresses for all records in our Client table would be updated to 23 Fingiertweg. That is very much not what we are looking to do.
Also note that we used «WHERE client_id = 101» in the UPDATE query. It would also have been possible to use «WHERE client_name = ‘Big Business Federation'» or «WHERE address = ‘123 Falschungstraße, 10999 Berlin'» or even «WHERE address LIKE ‘%Falschung%'».
The important thing is that the WHERE clause allows us to uniquely identify the record (or records) we want to update.
Deleting Records
It is also possible use our execute_query function to delete records, by using DELETE.
When using SQL with relational databases, we need to be careful using the DELETE operator. This isn’t Windows, there is no ‘Are you sure you want to delete this?’ warning pop-up, and there is no recycling bin. Once we delete something, it’s really gone.
With that said, we do really need to delete things sometimes. So let’s take a look at that by deleting a course from our Course table.
First of all let’s remind ourselves what courses we have.
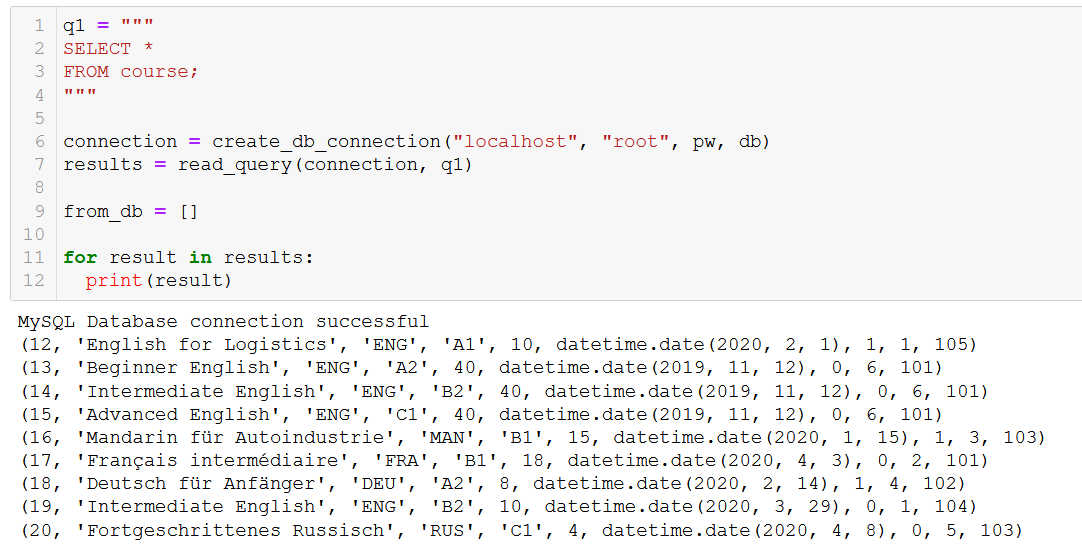
Let’s say course 20, ‘Fortgeschrittenes Russisch’ (that’s ‘Advanced Russian’ to you and me), is coming to an end, so we need to remove it from our database.
By this stage, you will not be at all surprised with how we do this — save the SQL command as a string, then feed it into our workhorse execute_query function.
Let’s check to confirm that had the intended effect:
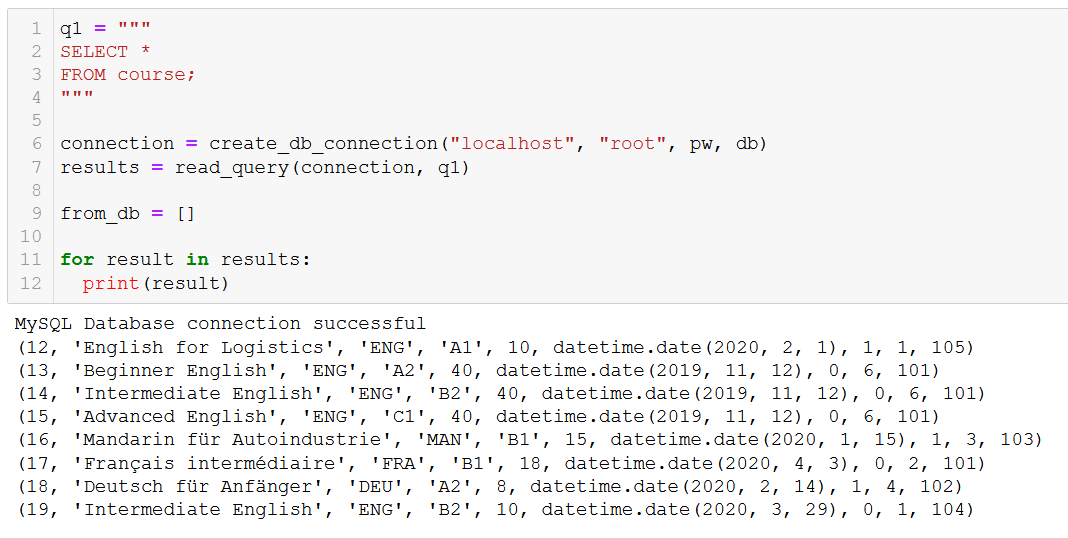
‘Advanced Russian’ is gone, as we expected.
This also works with deleting entire columns using DROP COLUMN and whole tables using DROP TABLE commands, but we will not cover those in this tutorial.
Go ahead and experiment with them, however — it doesn’t matter if you delete a column or table from a database for a fictional school, and it’s a good idea to become comfortable with these commands before moving into a production environment.
Oh CRUD
By this point, we are now able to complete the four major operations for persistent data storage.
We have learned how to:
- Create — entirely new databases, tables and records
- Read — extract data from a database, and store that data in multiple formats
- Update — make changes to existing records in the database
- Delete — remove records which are no longer needed
These are fantastically useful things to be able to do.
Before we finish things up here, we have one more very handy skill to learn.
Creating Records from Lists
We saw when populating our tables that we can use the SQL INSERT command in our execute_query function to insert records into our database.
Given that we’re using Python to manipulate our SQL database, it would be useful to be able to take a Python data structure (such as a list) and insert that directly into our database.
This could be useful when we want to store logs of user activity on a social media app we have written in Python, or input from users into a Wiki we have built, for example. There are as many possible uses for this as you can think of.
This method is also more secure if our database is open to our users at any point, as it helps to prevent against SQL Injection attacks, which can damage or even destroy our whole database.
To do this, we will write a function using the executemany() method, instead of the simpler execute() method we have been using thus far.
Now we have the function, we need to define an SQL command (‘sql’) and a list containing the values we wish to enter into the database (‘val’). The values must be stored as a list of tuples, which is a fairly common way to store data in Python.
To add two new teachers to the database, we can write some code like this:
Notice here that in the ‘sql’ code we use the ‘%s’ as a placeholder for our value. The resemblance to the ‘%s’ placeholder for a string in python is just coincidental (and frankly, very confusing), we want to use ‘%s’ for all data types (strings, ints, dates, etc) with the MySQL Python Connector.
You can see a number of questions on Stackoverflow where someone has become confused and tried to use ‘%d’ placeholders for integers because they’re used to doing this in Python. This won’t work here — we need to use a ‘%s’ for each column we want to add a value to.
The executemany function then takes each tuple in our ‘val’ list and inserts the relevant value for that column in place of the placeholder and executes the SQL command for each tuple contained in the list.
This can be performed for multiple rows of data, so long as they are formatted correctly. In our example we will just add two new teachers, for illustrative purposes, but in principle we can add as many as we would like.
Let’s go ahead and execute this query and add the teachers to our database.

Welcome to the ILS, Hank and Sue!
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
Conclusion
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
Как работать с базами данных SQL в Python
В инструкции научим работать с SQL: писать запросы, получать информацию из таблиц, а также познакомим с пакетами и библиотеками Python.
Введение
Сейчас в любой сфере деятельности человека необходима работа с большим объемом данных. Данные — это поддающееся многократной интерпретации представление информации, приведенное к формализованному виду, который будет пригоден для передачи или обработки. Для удобства использования огромных объемов данных была придумана структура, называемая база данных (БД). База данных — одна из ключевых компонент любой информационной системы.
Для управления базами используются системы управления базами данных (СУБД).
SQL-запросы
Близкое взаимодействие с базами данных неразрывно связано с SQL (Structured Query Language). С помощью него можно не только создать таблицу и заполнить ее уникальной информацией, но и «вытащить» из базы практически любую информацию, используя специальные запросы.
Инициализация таблицы в SQL
В базах данных таблицы представляют собой совокупность данных, хранящихся в структурированном виде. Большие базы данных состоят из множества таблиц, взаимосвязанных специальными видами связи. Для начала создадим таблицу с помощью SQL:
Рассмотрим подробнее этот обобщенный код. Команды, выделенные заглавными буквами, являются командами языка SQL. Разные виды БД поддерживают немного различающиеся команды, но большинство из них будет иметь CREATE TABLE.
Важно внимательно работать с типами столбцов, так как они могут отличаться. В нашем примере есть такие типы, как INTEGER для чисел, VARCHAR для строк и DATE для дат. Перед тем как использовать разные типы данных лучше ознакомиться с документацией, так как VARCHAR и DATE могут иметь свои особенности.
Созданная нами таблица будет состоять из четырех столбцов: уникальный идентификатор (будет являться основным ключом), имя, фамилия в строковом типе и дата рождения.
Также при добавлении новой таблицы мы можем задать столбец, в который необходимо будет записать значение. В противном случае при попытке оставить указанный столбец пустым, нам вернется ошибка. Здесь можно провести аналогию с формой регистрации на сайте, когда без указания номера телефона или электронной почты пользователь не сможет зарегистрироваться.
Введение данных в SQL
Сейчас наша таблица пустая. Поэтому сейчас научимся заполнять ее данными:
Для добавления новых данных в SQL нужно применять команду INSERT INTO. Также нужно указать, куда будут добавлены данные. При передаче неверного типа данных мы получим ошибку.
Обновление данных в SQL
Может возникнуть ситуация, когда какую-то часть данных необходимо поменять. Конечно, проще изменить данные выборочно, а не переписывать всю базу целиком.
После команды UPDATE мы обязательно пишем имя таблицы, где требуется обновить данные. После мы применяем SET во всех необходимых местах для замены обновленного значения. Если мы хотим внести изменения в конкретную строку, то нужно сообщить, куда мы собираемся внести правки. Например, в данном случае применяя WHERE, мы выбираем строку с id, равным 1. В результате будет только одна строка, так как подразумевается, что id — это уникальный идентификатор.
Чтение данных в SQL
При чтении данных нужно воспользоваться SELECT:
Так мы вернем все строки нашей таблицы, но в результате будут только две части информации: имя и фамилия. Если мы хотим получить все, что хранится в таблице, то можно воспользоваться запросом:
В этом случае звездочка означает, что мы намерены получить все имеющиеся в таблице столбцы.
Основные команды SQL
В SQL есть определенное количество команд, используя которые мы усложняем запросы. Комбинируя и правильно используя их, можно получить самые разные выборки данных в зависимости от потребностей. Давайте рассмотрим основные такие команды.
WHERE
Эту команду мы уже упоминали выше. С помощью нее мы указываем какое-то условие:
Условие может содержать сравнение текста или численных значений. Также допустимо использование классических логических операций: AND (и), OR (или) и NOT (отрицание).
GROUP BY
Оператор GROUP BY применяется для группировки выходных значений, в которых присутствуют агрегатные функции (например, COUNT, MAX, SUM, AVG и другие).
HAVING
По своей сути HAVING является аналогом WHERE. Это ключевое слово применяется вместе с GROUP BY. Это связано с тем, что команда WHERE не может использоваться с вышеперечисленными агрегатными функциями.
ORDER BY
ORDER BY применяется в том случае, когда к результату запроса нужно применить сортировку. По умолчанию команда отсортирует выходной результат в порядке возрастания. Однако можно указать способ сортировки с помощью ASC (по возрастанию) и DESC (по убыванию).
BETWEEN
BETWEEN применяется для выбора значений в определенном диапазоне. Этот оператор работает для чисел и строк, а также дат.
Оператор LIKE тоже используется в WHERE, когда задача требует задать шаблон для поиска.
Существует два свободных оператора, с помощью которых мы можем создавать определенные паттерны:
- % (любое количество символов (в том числе ни одного символа));
- _ (ровно один символ).
JOIN
JOIN применяется для соединения двух (и более таблиц), основываясь на общих атрибутах.
Вложенные подзапросы
Вложенные подзапросы — это запросы, включающие стандартные выражения SQL, вложенные в другой запрос. Это удобно использовать, если задача требует написать выделить какую-то информацию из результата другого запроса.
Удаление данных
Теперь мы умеем обрабатывать данные. Осталось научиться их удалять:
Такая команда удалит одну строку, id которой равно 1. Если необходимо удалить таблицу, то стоит применить DROP TABLE:
Однако можно очистить таблицу от данных, не удаляя ее саму:
С такими командами нужно работать предельно осторожно, ведь есть вероятность потерять важные данные. Чтобы избежать такой ситуации, следует всегда иметь актуальный бекап всей локальной базы данных.
API-модули
Python DB-API — это свод правил, которым следуют самостоятельные модули, задача которых заключается в реализации работы с БД. API-модулем мы называем программный интерфейс, посредством которого мы взаимодействуем с данными. Один принцип позволяет применять общий подход для разных БД. Поэтому для полноценной работы не нужно углубленно изучать каждую БД — достаточно разобраться с несколькими основными моментами.
adodbapi
Если возникает такая ситуация, где обязательно надо реализовать доступ через Microsoft ADO, то идеальным решением будет пакет adodbapi. И нельзя забывать, что adodbapi зависим от уже установленного PyWin32.Чтобы установить adodbapi, делаем следующее:
Чтобы все заработало, сначала импортируем библиотеку:
Далее мы указываем все необходимые для соединения данные: имя БД, строку подключения и название соответствующей таблицы.
После этого для связи с БД создаем подключение, где аргументом у метода connect() указываем строку связи:
Теперь создаем курсор — область памяти базы, предназначенная для хранения последнего оператора SQL. Иными словами, объект, отвечающий и за отправку запросов, и за получение их результатов.
Дальше мы уже можем передавать конкретные запросы и обрабатывать их вывод.
В конце обязательно завершаем подключение:
pyodbc
Сейчас ознакомимся с ODBC (Open Database Connectivity) — интерфейсом доступа к БД, разработанный в компании Microsoft. Суть ODBC заключается в разработке приложений для использования программного интерфейса доступа без опасений о различиях взаимодействия с разными источниками. Это достигается написанием драйверов, осуществляющих стандартные функции с учетом деталей реализации конкретного продукта. Самый используемый метод связи через ODBC — пакет pyodbc. Он устанавливается с помощью pip:
После установки импортируем библиотеку:
Далее необходимо написать строку связи:
В данном случае строка связи состоит из нескольких частей. Хорошей практикой будет сохранить все параметры в отдельный конфигурационный файл, в котором и будут храниться все необходимые параметры. Это добавит удобства при использовании и может обезопасить систему. После соединяемся с БД и получаем курсор:
Если мы успешно подключились, то, используя это соединение, мы можем применить курсор для получения ответа на запрос:
Теперь можно получить результат, вызвав методы fetchone() и fetchall(). Способы их использования мы рассмотрим чуть ниже.Так как не только базы данных от Microsoft поддерживают такой вид соединения, то пакет pyodbc можно использовать при работе и с другими базами данных, совместимыми с ODBC.
pypyodbc
Пакет pypyodbc можно назвать скриптом, написанным на Python. Интересно, что на самом деле pyodbc — это Python, завернутый в бэкэнд С++, в то время как pypyodbc уже является чистым кодом на Python. Чаще всего эти модули взаимозаменяемы. Единственное различие будет заключаться в импорте:
SQLite в Python
В отличие от других баз данных SQL, которые мы будем рассматривать дальше, у Python’a уже есть встроенная поддержка для SQLite — компактной встраиваемой СУБД. Для этой БД API-модулем будет sqlite3. Поэтому для корректной работы достаточно добавить импортирование стандартной библиотеки и ничего заранее устанавливать не нужно:
Подключение к базе данных
Далее обязательным этапом следует создание соединения:
Здесь мы указываем путь до файла базы данных. Следующим шагом требуется создать объект курсора:
Чтение из базы
Для чтения необходимо сделать следующее:
После вызова метода execute() мы уже пользуемся привычным синтаксисом SQL. Для получения ответа воспользуемся fetchall():
Так мы получаем все строки результата сделанного запроса. Важно помнить, что после того, как мы получили ответ на запрос из курсора, чтобы получить этот результат еще раз, необходимо повторно выполнить запрос. Иначе вернется пустой результат (null).
После окончания всех требуемых операций, обязательно нужно закрыть наше соединение:
Запись в базу
Аналогично чтению, для записи в БД нужно написать запрос к ней:
Однако, если мы не только читаем, но и вносим какие-либо изменения, обязательно нужно сохранить транзакцию:
Когда к базе установлено не одно соединение, а одно из них пытается как-то модифицировать данные, база данных SQLite блокируется до завершения или отмены текущей транзакции. Закончить транзакцию можно методом commit(), а отменить ее — методом rollback().
MySQL в Python
MySQL — это СУБД с открытым исходным кодом (open source). Ее можно подключить несколькими способами. Один из наиболее распространенных — это использование пакета MySQLdb, у которого существует несколько версий. Из-за наличия различных версий, часть из которых несовместима с конкретными версиями Python, может возникнуть путаница.
Поэтому рассмотрим подробно один конкретный пакет mysqlclient — ответвление MySQL-Python (как раз MySQLdb), которое предоставляет поддержание Python 3. Важно отметить, что нам понадобится MySQL или MySQL Client для его успешной установки:
После этого пакет mysqlclient будет установлен. Теперь посмотрим, как работа с этим пакетом будет реализована в коде:
Так мы подключаем сам пакет.
Этой строчкой мы создаем соединение. Обязательно указываем сервер, куда подключаемся, логин и пароль для соединения, а также название таблицы, с которой будем осуществлять взаимодействие.
Курсор создан. Можно начинать выполнять конкретные запросы.
Здесь мы извлекаем только одну строку из всего результата и дальше можем обрабатывать ее так, как требует решаемая задача.
Не забываем закрыть связь с БД.
PostgreSQL в Python
PostgresSQL является еще одной БД, распространяемой как свободное программное обеспечение, широко используемое в разработке. У Python существует несколько пакетов, которые поддерживают этот бэкэнд, но мы изучим работу с одним из них — Psycopg. Аналогично другим пакетам для начала необходимо его установить:
Уже в коде будет необходимо импортировать этот пакет:
После этого аналогично работе с MySQL мы передаем в переменную connect соединение:
Что делать дальше нам уже известно — создавать курсор:
Далее посмотрим на этот фрагмент кода:
С помощью метода execute() мы делаем запрос к БД. После этого получаем одну строку результата с помощью fetchone(). После чего разрываем подключение к базе данных, закрывая и курсор, и соединение.
За исключением нескольких особенностей, работа с Psycopg практически не отличается от работы с другими пакетами. Мы помним, что и mysqlclient, и Psycopg следуют стандартному API, которому, на самом деле, следует большая часть пакетов. Именно поэтому код взаимодействия с разными БД практически не отличается между собой. Так мы можем подтвердить, что несмотря на существующие различия, работа с разными пакетами сводится к нескольким одинаковым командам.
Расширенные методы курсора
Теперь рассмотрим особые возможности курсора, которые могут помочь при взаимодействии с базой данных.
Разбивка запроса на строки
Часто приходится писать длинные SQL-запросы, состоящие из множества строк. К сожалению, при написании запроса в одну строку теряется читабельность. Поэтому в коде удобно разбить такой запрос на несколько строчек, заключив его в тройные кавычки:
Объединение запросов к БД
Метод execute() позволяет выполнить за раз лишь один запрос (если написать сразу несколько запросов, разделив их точкой с запятой или другим разделителем, то мы получим ошибку). Однако чаще всего в разработке требуется обратиться к БД далеко не один раз. Конечно, можно просто вызвать этот метод несколько раз подряд:
Но можно воспользоваться более изящным решением и вызвать executescript():
Также этот метод может помочь в том случае, если мы сохранили тело запроса в файл или отдельную переменную.
Подстановка значения в запрос
В процессе написания кода, в котором мы тесно взаимодействуем с БД, может возникнуть ситуация, когда необходимо подставить конкретное значение в запрос. Тогда поможет применение второго аргумента в методе execute():
Или есть еще один способ:
Важно! В PostgreSQL и в MySQL для подстановки вместо знака ‘?’ нужно писать %s.
Также стоит отметить, что этот способ не подойдет для замены названия таблицы.
Множественная вставка строк
Для вставки нескольких строк воспользуемся методом executemany(), в который в независимости от количества значений необходимо передавать список кортежей:
В этом примере мы как раз используем кортеж (поэтому после имени пользователя идет запятая), несмотря на то что передаем только одно значение. После этого вставляем полученный список:
Таким образом, проходясь по списку, мы вставляем сразу несколько строк.
Повышение устойчивости кода
Сейчас в любом проекте требуется правильно обрабатывать и отлавливать возможные ошибки во время исполнения программы. Особенно это может быть критично при записи информации в базу данных. Поэтому полезно оборачивать обращение к БД в конструкцию «try-except-else»:
Подробнее рассмотрим этот фрагмент. В try мы передаем инструкцию для SQL, после чего записываем в result весь результат. При возникновении ошибки мы используем встроенный в sqlite3 объект ошибок и печатаем его в консоль. В противном случае, если же все отработало корректно, мы сохраняем изменения. Такой подход может сильно упростить исправление ошибок в ходе разработки.
Создание таблиц
Перед нами стоит простая задача: создать таблицу. На примере этой задачи мы окончательно разберемся в принципе работы с БД в Python. Ниже посмотрим на функцию, задача которой будет осуществлять работу с такими БД, как SQLite и MySQL (для PostgreSQL будет незначительно отличаться несколькими строчками):
В аргументы execute_query() мы передаем соединение и сам запрос. Дальше с помощью курсора мы исполняем запрос и сохраняем транзакцию. Также сразу обрабатываем ошибки, которые могут возникнуть.
Выше мы уже подробно изучили, что делает каждая строчка кода, здесь же все объединено в одну функцию для удобства написания кода. Теперь осталось написать сам запрос, который будет создавать новую таблицу:
В этом запросе мы создаем таблицу клиентов, у каждого из которых будет свой id (генерирующийся самостоятельно), имя, фамилия и возраст. Осталось вызвать execute_query():
Все, новая таблица будет создана.
Работа с записями в БД с помощью Python
Теперь мы уже можем подвести итог о принципе работы Python с базами данных. Вне зависимости от того, какую цель мы преследуем и какие действия мы хотим сделать с таблицей, все сводится к отправлению запросов на SQL, которые мы передаем в курсор. Далее мы кратко рассмотрим примеры, связанные с различными операциями с таблицами.
Мы уже знаем, что в зависимости от конкретной задачи будет изменяться только SQL-запрос. Поэтому ниже посмотрим на соответствующие запросы для разных подзадач.
Добавление записей
Внутри запроса мы добавляем в таблицу customers трех человек, для каждого указывая имя, фамилию и возраст. Осталось передать этот запрос в execute_query(), как мы делали выше.
Обновление данных
В этом запросе мы изменяем имя клиенту с id равном 2. При передаче этого запроса в функцию мы успешно обновим информацию в таблице.
Чтение данных
Выполняя этот запрос, мы получим всех клиентов, информация о ком хранится в таблице.
Удаление данных
А теперь удалим клиента с id равным 1.
Дополнительные возможности SQLite
SQLite широко используется и легко поддерживается большинством клиентов SQL. Рассмотрим некоторые интересные возможности SQLite.
Подключение к БД из клиента SQL
Если мы запускаем Python на локальном компьютере, то с помощью какого-нибудь клиента SQL можно напрямую подключиться к файлу БД. Одним из таких клиентов является приложение DBeaver, позволяющий управлять базой данных.
Алгоритм работы как и раньше: сначала нужно создаем новое соединение: правой кнопкой мыши по названию БД (при установке DBeaver предлагает создать тестовую базу данных, чтобы ознакомиться с функционалом приложения) → Создать → Соединение:

После выбора подходящей нам базы данных SQLite, мы нажимаем Далее и в специальном окне настраиваем соединение нужным нам образом:
После завершения всех настроек и указания верных путей мы уже можем сделать любой SQL-запрос.
Интеграция с фреймворком Pandas
На самом деле в Python есть библиотека, специально предназначенная для обработки и анализа структурированных данных. Библиотека Pandas — это гибкий и мощный инструмент, широко применяемый в анализе данных.
В фреймворке Pandas есть множество специальных структур и операций для эффективной работы с данными. Основополагающей частью Pandas является фрейм данных (от DataFrame) — структура, представляющая собой двумерный набор данных, хранящихся в табличной форме. Но также фрейм данных непрерывно интегрируется с SQLite.
Как мы уже привыкли, сначала нужно импортировать библиотеку:
Для демонстрации этого сначала определим какой-нибудь фрейм данных:
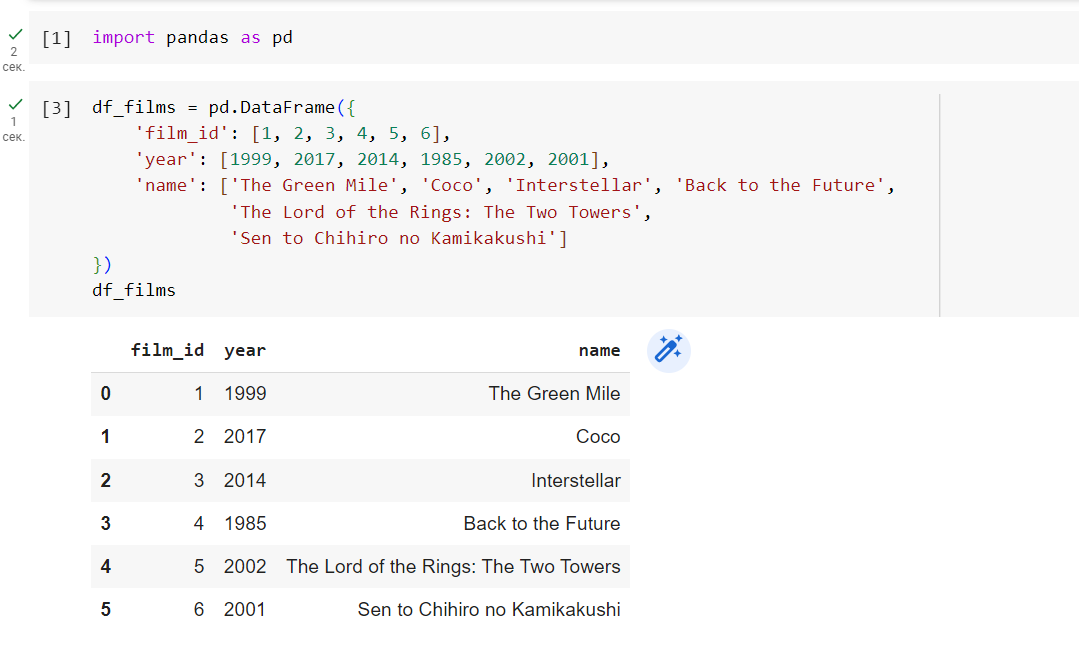
Также мы могли прочитать дата фрейм из файла с расширением csv:
Теперь у нас есть небольшой фрейм данных, посвященный фильмам. У фрейма есть метод to_sql(), позволяющий сохранить его в БД. Воспользуемся им:
Теперь у нас есть таблица в нашей БД, соединение с которой мы передали в аргументы метода. Длина столбцов и типы данных будут сгенерированы автоматически. Но если появится такая необходимость, конечно, их можно будет изменить.
Если же мы хотим написать какой-то SQL-запрос к таблице, то это также легко делается с помощью метода read_sql():
Можем сделать вывод, что с помощью библиотеки Pandas можно очень просто реализовать работу с реляционной базой данных SQLite.
Заключение
Мы тесно поработали с SQL, научились писать запросы, используя специальные операторы и теперь умеем получать самую разную информацию из таблиц в зависимости от поставленной задачи.
Также в этой статье мы ознакомились с разнообразными пакетами и библиотеками языка Python, позволяющими реализовать и упростить неочевидное взаимодействие с базами данных SQL. Python позволяет без труда совершать множество операций, начиная от создания таблиц и заканчивая модификацией строк в уже существующих записях.
Зарегистрируйтесь в панели управления
И уже через пару минут сможете арендовать сервер, развернуть базы данных или обеспечить быструю доставку контента.
Как подружить sql и python

Python is a high-level, general-purpose, and very popular programming language. Basically, it was designed with an emphasis on code readability, and programmers can express their concepts in fewer lines of code. We can also use Python with SQL. In this article, we will learn how to connect SQL with Python using the ‘MySQL Connector Python module. The diagram given below illustrates how a connection request is sent to MySQL connector Python, how it gets accepted from the database and how the cursor is executed with result data.
SQL connection with Python
Connecting MySQL with Python
To create a connection between the MySQL database and Python, the connect() method of mysql.connector module is used. We pass the database details like HostName, username, and the password in the method call, and then the method returns the connection object.
The following steps are required to connect SQL with Python:
Step 1: Download and Install the free MySQL database from here.
Step 2: After installing the MySQL database, open your Command prompt.
Step 3: Navigate your Command prompt to the location of PIP. Click here to see, How to install PIP?
Step 4: Now run the commands given below to download and install “MySQL Connector”. Here, mysql.connector statement will help you to communicate with the MySQL database.
Download and install “MySQL Connector”
Step 5: Test MySQL Connector
To check if the installation was successful, or if you already installed “MySQL Connector”, go to your IDE and run the given below code :
If the above code gets executed with no errors, “MySQL Connector” is ready to be used.
Базы данных в Python

Эта статья о том, как работать с базами данных в Python. Эта статья носит, скорее, вступительный характер. Вы не изучите весь язык SQL, вместо этого, я дам вам развернутое представление о командах SQL и затем мы научимся подключаться к нескольким популярным базам данных в Python. Большая часть баз данных использует базовые команды SQL одинаково, но они также могут использовать специальные команды для бекенда той или иной базы данных, или просто работают с некоторыми отличиями. Рекомендую ознакомиться с документацией к базам данных, если у вас возникнут проблемы. Мы начнем статью с изучения базового синтаксиса SQL.
Базовый синтаксис SQL
SQL расшифровывается как Structured Query Language (язык структурированных запросов). Это, в сущности, де-факто язык для взаимодействия с базами данных и является примитивным языком программирования. В данном разделе мы рассмотрим основы CRUD (Create, Read, Update и Delete). Это самые важные функции, которые вам нужно освоить, перед тем как использовать базы данных в Python. Конечно, вам также понадобится узнать как создавать запросы, но мы рассмотрим это по ходу дела, когда нужно будет выполнять запрос для чтения, обновления или удаления.
Создание таблицы
Первое что вам нужно для базы данных – это таблица. Это место, где ваши данные будут организованы и храниться. Большую часть времени вам будут нужны несколько таблиц, в каждой из которых будут храниться поднастройки ваших данных. Создание таблицы в SQL это просто. Все что вам нужно сделать, это следующее:
Это довольно обобщенный код, но он работает в большей части случаев. Первое, на что стоит обратить внимание – куча слов прописанных заглавными буквами. Это команды SQL. Их не всегда нужно вписывать через капс, но мы сделали это, чтобы помочь вам увидеть их. Я также хочу обратить внимание на то, что каждая база данных поддерживает слегка отличающиеся команды. Большинство будет содержать CREATE TABLE, но типы столбцов баз данных могут быть разными. Обратите внимание на то, что в этом примере у нас есть базы данных INTEGER, VARCHAR и DATE.
DATE может вызывать много разных штук, как и VARCHAR. Проконсультируйтесь с документацией на тему того, что вам нужно делать. В любом случае, в этом примере мы создаем базу данных с пятью столбцами. Первый – это id, который мы настраиваем в качестве нашего основного ключа. Он не должен быть NULL, но мы и не указываем, что в нем, так как еще раз, каждый бекенд базы данных выполняет работу по-разному, или делает это автоматически для нас. Остальные столбцы говорят сами за себя
Введение данных
Сейчас наша база данных пустая. Это не очень полезно в использовании, так что в этом разделе мы научимся добавлять данные в базу. Вот общая идея:
SQL использует команды INSERT INTO для добавления данных в определенную базу данных. Вы также указываете, в какие столбцы вы добавляете данные. Когда мы создаем таблицу, мы можем определить необходимый столбец, который может вызвать ошибку, если мы не добавим в него необходимые данные. Однако, мы не делали этого в нашем определении таблицы ранее. Это просто на заметку. Вы также получите ошибку, если передадите неправильный тип данных, от этой вредной привычки я не мог отвыкнуть целый год. Я передавал строку или varchar, вместо данных. Конечно, каждая база данных требует определенный формат этих самых данных, так что вам может понадобиться разобраться с тем, что именно значит DATE для вашей базы данных.
Обновление данных
Представим, что мы сделали опечатку в нашем INSERT. Чтобы это исправить, нам нужно использовать команду SQL под названием UPDATE:
Команда UPDATE говорит нам, какая таблица нуждается в обновлении. Далее мы используем SET в одном или более столбцах для вставки нового значения. Наконец, на нужно указать базе данных ту строку, которую мы хотим обновить. Мы можем использовать команду WHERE, чтобы указать базе данных, что мы хотим изменить строчку, Id которой является 1.
Чтение данных
Чтение данных нашей базы данных осуществляется при помощи оператора SQL под названием SELECT:
Так мы возвращаем все строчки из нашей базы данных, но результат будет содержать только три части данных: название, создание и модель. Если вы хотите охватить все данные в базе данных, вы можете выполнить следующее:
Звездочка в данном случае это подстановка, которая говорит SQL, что вы хотите охватить все столбцы. Если вы хотите ограничить выбранный вами охват, вы можете добавить команду WHERE в вашем запросе:
Так мы получим информацию о названии, создании и модели для 2000-2006 годов. Существует ряд других команд SQL, которые помогут вам в работе с запросами. Убедитесь, что ознакомитесь с такими командами как BETWEEN, LIKE, ORDER BY, DISTINCT и JOIN.
Удаление данных
Возможно, вам понадобиться удалить данные из вашей базы данных. Как это сделать:
Этот код удалит все строчки, в поле названия которых указано «Ford» из нашей таблицы. Если вы хотите удалить всю таблицу, вы можете воспользоваться оператором DROP:
Используйте DROP и DELETE осторожно, так как вы легко можете потерять все данные, если вызовете оператор неправильно. Всегда держите хороший, годный, проверенный бекап вашей базы данных.
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
adodbapi
В версиях Python2.4 и 2.5, мне нужно было подключаться к серверу SQL 2005 и Microsoft Access, и один из них или оба были настроены только для использования методологии подключения Microsoft к ADO. На то время решением было использовать пакет adodbapi. Этот пакет следует использовать тогда, когда вам нужно получить доступ к базе данных через Microsoft ADO. Я заметил, что этот пакет не обновлялся с 2014 года, так что помните об этом. К счастью, вам не нужно использовать этот пакет, так как Microsoft также предоставляет драйвер связи ODBC, но если по какой-то причине вам нужно поддерживать только ADO, то этот пакет – то, что вам нужно!
Запомните: adodbapi зависит от наличия установленного пакета PyWin32.
Для установки adodbapi, вам нужно сделать следующее:
Давайте посмотрим на простой пример, который я использую для связи с Microsoft Access на протяжении длительного времени:
Сначала мы создаем строку соединения. Эти строки определяют, как связаться с Microsoft Access или сервером SQL. В данном случае, мы подключаемся к Access. Для непосредственной связи с базой данных, вы вызываете метод connect и передаете ему вашу строку связи. Теперь у вас есть объект соединения, но для взаимодействия с базой данных вам нужен курсор. Его мы и создаем. Следующая часть – написание запроса SQL. В данном случае мы используем всю базу данных, так что мы выделяем * и передаем этот оператор SQL методу execute нашего курсора. Для получения результата мы вызываем fetchall, который возвращает весь результат. Наконец, мы закрываем cursor и connection. Если вы используете пакет adodbapi, я настоятельно рекомендую пройтись по справочному документу. Это очень полезно для понимания пакета, так как он не слишком хорошо документирован.
pyodbc
ODBC (Open Database Connectivity) – это стандартный API для доступа к базам данных. Большая часть баз данных продукции включает драйвер ODBC, который вы можете установить для связи с базой данных. Один из самых популярных методов связи с Python через ODBC – это пакет pyodbc. В соответствии с его страницей на Python Packaging Index, вы можете использовать его как на Windows, так и Linux. Пакет pyodbc реализует спецификацию DB API 2.0. Вы можете установить pyodbc при помощи pip:
Давайте взглянем на довольно обобщенный способ подключения к серверу SQL при помощи pyodbc и выберем какие-нибудь данные, как мы делали это в разделе adodbapi:
В данном коде мы создаем очень длинную строку связи. У нее много частей. Драйвер, сервер, номер порта, название базы данных, пользователь и пароль. Возможно, вам захочется сохранить большую часть этой информации в какой-нибудь файл конфигурации, так что вам не нужно будет вводить эту строку каждый раз. Желательно не перемудрить с именем пользователя и паролем. После получения нашей строки связи, мы попытаемся соединиться с базой данных, вызвав функцию connection. Если подключение прошло удачно, то мы получаем объект подключения, который мы можем использовать для создания объекта курсора. Теперь у нас есть курсор, мы можем запросить базу данных и запустить любые команды, которые нам нужны, в зависимости от того, какой доступ у базы данных. В этом примере, мы запускаем SELECT * для извлечения всех строчек. Далее мы демонстрируем нашу возможность брать по одной строчке за раз и вытягивать их через fetchone и fetchall соответственно. Также у нас в распоряжении имеется функция fetchmany, которую вы можете использовать для определения того, как много строчек вам нужно вернуть. Если вы имеете дело с базой данных, которая работает с ODBC, вы также можете использовать данный пакет. Обратите внимание на то, что базы данных Microsoft не единственные поддерживают данный метод соединения.
pypyodbc
Пакет pypyodbc, по сути, чистый скрипт Python. Это, в целом, переопределенный pyodbc чисто под Python. Это значит, что pyodbc – это Python, обернутый в бекенд C++, в то время как pypyodbc это чистый код Python. Он поддерживает тот же API, как и предыдущий модуль, так что эти модули взаимозаменяемые в большинстве случаев. В связи с этим, я не буду показывать никаких примеров в данном разделе, так как единственная разница между ними – это импорт.
MySQL в Python
MySQL – это очень популярный бекенд баз данных с открытым кодом. Вы можете подключить его к Python несколькими различными путями. Например, вы можете подключить его, используя один из методов ODBC, которые я упоминал в последних двух разделах. Один из наиболее популярных способов подключения MySQL к Python это пакет MySQLdb. Существует несколько вариантов того пакета:
- MySQLdb1
- MySQLdb2
- moist
Первый – это привычный способ подключения MySQL к Python. Однако, в основном он используется только в разработке и на данный момент не получает никаких новых функций. Разработчики переключились на MySQLdb2, и преобразовали его в проект moist. В MySQL произошел раскол после того, как их купили Oracle, что привело к разветвлению на проект, который называется Maria. Так что мы имеем дело с проектами MariaDB, MySQL и еще одной веткой, под названием Drizzle, каждая из которых, в той или иной мере основана на исходном коде MySQL. Проект moist направлен на создание моста, который мы можем использовать для соединения со всеми этими бекендами, к тому же, он все еще находится на этапах альфа или бета с момента публикации. Путаницу также создает тот факт, что MySQLdb завернут в _mysql, который вы можете использовать напрямую, если это нужно. В любом случае, вы быстро заметите, что MySQLdb не совместим с Python 3, вообще. Совместимость с проектом moist скоро будет, но пока её нет. Итак, как же работать с Python 3? У вас есть несколько вариантов:
- mysql-connector-python
- pymysql
- CyMySQL
- mysqlclient
mysqlclient – это ответвление MySQL-Python (другими словами, MySQLdb), который обеспечивает поддержку Python 3. Это метод, который проект Django рекомендует для подключения к MySQL. Так что мы сфокусируемся на этом пакете в данном разделе. Обратите внимание на то, что вам понадобится установленный MySQL или MySQL Client для успешной установки пакета mysqlclient. Если вы уже сделали это ранее, то вам остается только использовать pip для установки: